核心概念:在哪个环节进行替换?
在织梦采集流程中,替换主要发生在两个关键位置:
- “高级选项”中的“内容替换”:这是最常用、最核心的替换功能,它作用于采集到的每一条记录的内容字段(比如文章正文、描述等),这个替换是在你设置好采集规则、获取到内容后,在保存到网站数据库之前进行的。
- “发布规则”中的“内容正文处理”:这个功能更侧重于在你将文章发布到网站栏目后,对已生成的HTML页面进行二次处理,它通常用于移除一些特定的、可能在前端显示时才暴露出问题的代码。
我们主要讲解第一种,即“高级选项”里的“内容替换”,因为它能从源头上控制数据质量。
如何进入并使用“内容替换”功能?
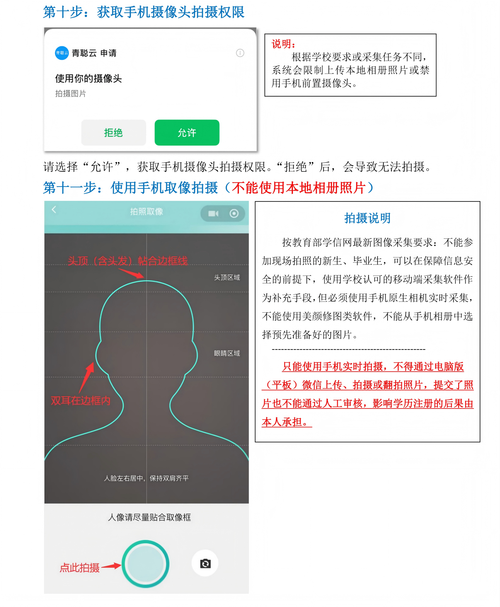
- 登录织梦后台,在左侧菜单栏找到 【采集】 -> 【采集侠】 或 【采集管理】。
- 点击 【增加新采集任务】 或编辑一个已有的采集任务。
- 在设置采集规则时,切换到 【高级选项】 这个标签页。
- 向下滚动,你会找到 替换】 这个区域,这里就是我们的主战场。
替换”区域详解
这个区域由三部分组成:过滤”、“内容替换” 和 “保留HTML标签”。
内容过滤
这个功能用于删除你不想要的代码或文本,它支持正则表达式,非常强大。
-
作用:直接移除匹配到的内容。
 (图片来源网络,侵删)
(图片来源网络,侵删) -
常用场景:
- 删除广告代码:采集站常常在文章开头、结尾或中间插入
<iframe>、<script>、<div class="ad">等广告。 - 删除无关链接:移除一些版权声明或推广链接。
- 删除特定文本:比如删除文章末尾的“本文来源:XXX网”。
- 删除广告代码:采集站常常在文章开头、结尾或中间插入
-
示例:
- 删除所有
<script>标签及其内容:- 在过滤框中输入:
<script.*?</script> - 注意:勾选 “使用正则表达式”。
- 在过滤框中输入:
- 删除所有 class 为
ad的 div:- 输入:
<div[^>]*class="ad"[^>]*>.*?</div> - 注意:同样要勾选“使用正则表达式”。
- 输入:
- 删除文章末尾的特定文本:
- 输入:
本文来源:XXX网 - 这个可以不用正则,直接匹配文本。
- 输入:
- 删除所有
内容替换
这个功能用于查找并替换文本,即“查找 A,替换成 B”。
-
作用:将 unwanted 内容替换成你想要的内容或留空。
-
常用场景:
- 替换域名:将采集站的外部链接(如图片、其他文章链接)替换成你自己的域名,实现“内链”或“防盗链”。
- 修正错误编码:将采集来的
替换成空格,&替换成&等。 - 添加版权信息:在文章末尾自动加上你的版权声明。
-
示例:
- 将采集站的图片链接替换为自己的:
- :
http://www.original-website.com/images/ - 替换为:
http://www.your-website.com/uploads/ - 效果:文章中所有指向原网站的图片路径都会被修改成你网站的路径。
- :
- 删除多余的空行:
- :
\n\n\n(三个换行符) - 替换为:
\n(一个换行符) - 注意:需要勾选“使用正则表达式”。
- :
- 在文章末尾添加版权:
- :
</p>(文章末尾的最后一个段落标签) - 替换为:
</p><p>本文原创,转载请注明来自<a href="http://www.your-website.com">我的网站</a>。</p> - 注意:这个操作相对复杂,更推荐在发布规则或通过二次开发实现。
- :
- 将采集站的图片链接替换为自己的:
保留HTML标签
这是一个白名单功能,非常安全。
-
作用:如果你只希望文章中保留某些特定的HTML标签(
<p>,<br>,<strong>,<img>),可以在这里填写,其他所有标签(包括<script>,<div>,<span>等)都会被自动删除。 -
常用场景:
- 极度净化内容:当你对采集内容不信任,或者网站样式非常简单,只需要纯文本和基本排版时使用。
- 防止XSS攻击:通过移除所有潜在危险的标签(如
<script>,<iframe>)来提高网站安全性。
-
示例:
- 只保留段落、换行、加粗、图片和超链接标签。
- 在框中输入:
p,br,strong,img,a - 注意:标签之间用英文逗号 隔开,不要加
<和>。
实战演练:一个完整的替换方案
假设我们要采集一篇新闻文章,目标是得到一个干净的、适合发布的版本。
采集到的原始内容可能包含:
<script src='http://ad.original.com/ad.js'></script>
<div class="article-content">
<p>这是一篇关于<strong>织梦CMS</strong>的教程。</p>
<p>文章中可能会提到 <a href="http://www.original.com/page1">这个链接</a>。</p>
<p>可能会有一些无关的文本。</p>
<p>本文来源:XXX新闻网</p>
</div>
我们的目标:
-
删除
<script>广告代码。 -
删除底部的版权声明文本。
-
将外部链接
http://www.original.com/page1替换为你网站上的相关文章链接。 -
只保留
<p>,<strong>,<a>,<img>标签,确保安全。 替换”区域的设置如下:** -
内容过滤:
- 在第一个输入框中输入:
<script.*?</script> - 勾选 “使用正则表达式”。
- 在第二个输入框中输入:
本文来源:XXX新闻网 - (可以不勾选正则,直接匹配文本)。
- 在第一个输入框中输入:
-
内容替换:
- :
http://www.original.com/page1 - 替换为:
/view-123-1.html(你网站上的文章链接) - (不需要正则)。
- :
-
保留HTML标签:
- 在框中输入:
p,strong,a,img
- 在框中输入:
最终保存到数据库的内容将会是:
<div class="article-content">
<p>这是一篇关于<strong>织梦CMS</strong>的教程。</p>
<p>文章中可能会提到 <a href="/view-123-1.html">这个链接</a>。</p>
<p>可能会有一些无关的文本。</p>
</div>
可以看到,广告和版权声明被移除了,外部链接被替换,并且因为开启了“保留HTML标签”,多余的 <div> 也被去除了,内容变得非常干净。
高级技巧与注意事项
-
正则表达式是核心:要玩转织梦采集,必须掌握一些基础的PCRE正则表达式。
- 匹配除换行符外的任何字符。
- 匹配前面的子表达式零次或多次。
- 匹配前面的子表达式零次或一次,或指明一个非贪婪限定符。
- 是一个常见的“非贪婪”匹配模式,它会匹配尽可能少的字符,非常适合用于匹配标签对。
-
测试、测试、再测试:
- 在正式采集前,务必使用 【测试采集】 功能。
- 仔细检查“内容替换”后的结果是否符合预期,如果不对,返回修改规则,再次测试,直到完美。
-
顺序很重要:织梦会按照你设置的顺序依次执行“内容过滤”和“内容替换”规则,通常是先过滤掉垃圾,再替换掉需要修改的内容。
-
善用“发布规则”替换”无法解决某些问题(比如替换文章标题中的特定字符),可以在“发布规则”->“内容正文处理”中再次进行操作,或者使用更强大的自动摘要”功能。
-
注意编码问题:有时采集下来的是乱码,除了在“高级选项”->“文档编码”处设置正确的编码外,也可以在“内容替换”中尝试用正则替换掉错误的字符编码标记。
通过以上详细的讲解和示例,相信你已经对织梦后台的采集替换功能有了全面而深入的理解,熟练运用这些技巧,你就能高效地获取到高质量、纯净的内容,大大减少后期手动编辑的工作量。


