目录
- 核心基础:C 语言的关键特性
- 数据结构
- 线性结构
- 数组
- 链表
- 单向链表
- 双向链表
- 循环链表
- 栈
- 队列
- 普通队列
- 循环队列
- 非线性结构
- 树
- 二叉树
- 二叉搜索树
- 堆
- 最大堆
- 最小堆
- 图
- 树
- 线性结构
- 算法
- 排序算法
- 冒泡排序
- 选择排序
- 插入排序
- 归并排序
- 快速排序
- 查找算法
- 顺序查找
- 二分查找
- 图算法
- 深度优先搜索
- 广度优先搜索
- 排序算法
- 学习建议与实践项目
核心基础:C 语言的关键特性
在用 C 语言实现数据结构时,以下几个概念至关重要:
(图片来源网络,侵删)
- 指针:C 语言的灵魂,数据结构的核心就是管理内存中的数据块,而指针正是用来引用这些内存地址的工具,链表、树、图等结构完全依赖指针来建立元素之间的连接。
- 结构体:用于将不同类型的数据组合成一个单一的类型,一个链表的节点可以包含一个数据域和一个指向下一个节点的指针域,这两个域就可以用一个结构体来定义。
- 内存管理:C 语言允许你手动申请和释放内存。
malloc(): 在堆上分配一块指定大小的内存。calloc(): 在堆上分配一块指定大小的内存,并初始化为 0。free(): 释放之前通过malloc或calloc分配的内存。- 忘记
free()会导致内存泄漏,这是 C 语言编程中最常见的错误之一。
- 函数指针:在实现高级算法(如回调函数、比较函数)时非常有用。
数据结构
线性结构
1 数组
数组是连续内存中存储相同类型元素的集合。
- 特点:
- 内存连续。
- 支持随机访问,通过索引可以在 O(1) 时间内访问任意元素。
- 大小固定(静态数组),或在扩容时需要重新分配内存(动态数组)。
- C 语言实现: C 语言原生支持数组,下面是一个简单的动态数组实现,包含扩容功能。
#include <stdio.h>
#include <stdlib.h>
// 动态数组结构体
typedef struct {
int *data; // 指向数组元素的指针
size_t size; // 当前元素个数
size_t capacity; // 当前容量
} DynamicArray;
// 初始化动态数组
void initArray(DynamicArray *arr, size_t initialCapacity) {
arr->data = (int *)malloc(initialCapacity * sizeof(int));
arr->size = 0;
arr->capacity = initialCapacity;
}
// 向数组末尾添加元素
void push_back(DynamicArray *arr, int value) {
if (arr->size == arr->capacity) {
// 容量不足,扩容为原来的2倍
arr->capacity *= 2;
arr->data = (int *)realloc(arr->data, arr->capacity * sizeof(int));
}
arr->data[arr->size++] = value;
}
// 释放动态数组内存
void freeArray(DynamicArray *arr) {
free(arr->data);
arr->data = NULL;
arr->size = arr->capacity = 0;
}
int main() {
DynamicArray myArray;
initArray(&myArray, 2);
push_back(&myArray, 10);
push_back(&myArray, 20);
push_back(&myArray, 30); // 触发扩容
for (size_t i = 0; i < myArray.size; i++) {
printf("%d ", myArray.data[i]);
}
printf("\n");
freeArray(&myArray);
return 0;
}
2 链表
链表由一系列节点组成,每个节点包含数据和指向下一个节点的指针,内存是非连续的。
- 特点:
- 内存不连续,通过指针链接。
- 插入和删除元素高效(O(1),已知节点位置时)。
- 不支持随机访问,访问元素需要 O(n) 时间。
- C 语言实现:单向链表
#include <stdio.h>
#include <stdlib.h>
// 链表节点结构体
typedef struct Node {
int data;
struct Node *next;
} Node;
// 创建新节点
Node* createNode(int data) {
Node *newNode = (Node *)malloc(sizeof(Node));
if (!newNode) {
perror("Memory allocation failed");
exit(EXIT_FAILURE);
}
newNode->data = data;
newNode->next = NULL;
return newNode;
}
// 在链表头部插入节点
void insertAtHead(Node **head, int data) {
Node *newNode = createNode(data);
newNode->next = *head;
*head = newNode;
}
// 打印链表
void printList(Node *head) {
Node *current = head;
while (current != NULL) {
printf("%d -> ", current->data);
current = current->next;
}
printf("NULL\n");
}
// 释放链表内存
void freeList(Node *head) {
Node *current = head;
while (current != NULL) {
Node *temp = current;
current = current->next;
free(temp);
}
}
int main() {
Node *head = NULL;
insertAtHead(&head, 30);
insertAtHead(&head, 20);
insertAtHead(&head, 10);
printList(head); // 输出: 10 -> 20 -> 30 -> NULL
freeList(head);
return 0;
}
3 栈
栈是一种 后进先出 的数据结构。
- 特点:主要操作是
push(入栈) 和pop(出栈),都在栈顶进行。 - C 语言实现:可以用数组或链表实现,这里用数组实现。
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#define CAPACITY 5
typedef struct {
int items[CAPACITY];
int top;
} Stack;
void initStack(Stack *s) {
s->top = -1;
}
bool isEmpty(Stack *s) {
return s->top == -1;
}
bool isFull(Stack *s) {
return s->top == CAPACITY - 1;
}
void push(Stack *s, int value) {
if (isFull(s)) {
printf("Stack Overflow!\n");
return;
}
s->items[++s->top] = value;
}
int pop(Stack *s) {
if (isEmpty(s)) {
printf("Stack Underflow!\n");
return -1;
}
return s->items[s->top--];
}
int peek(Stack *s) {
if (isEmpty(s)) {
printf("Stack is empty!\n");
return -1;
}
return s->items[s->top];
}
int main() {
Stack s;
initStack(&s);
push(&s, 10);
push(&s, 20);
push(&s, 30);
printf("Top element: %d\n", peek(&s)); // 30
printf("Popped: %d\n", pop(&s)); // 30
printf("Popped: %d\n", pop(&s)); // 20
push(&s, 40);
printf("Top element: %d\n", peek(&s)); // 40
return 0;
}
4 队列
队列是一种 先进先出 的数据结构。

(图片来源网络,侵删)
- 特点:主要操作是
enqueue(入队) 和dequeue(出队)。 - C 语言实现:循环队列
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#define CAPACITY 5
typedef struct {
int items[CAPACITY];
int front;
int rear;
int size;
} Queue;
void initQueue(Queue *q) {
q->front = 0;
q->rear = -1;
q->size = 0;
}
bool isEmpty(Queue *q) {
return q->size == 0;
}
bool isFull(Queue *q) {
return q->size == CAPACITY;
}
void enqueue(Queue *q, int value) {
if (isFull(q)) {
printf("Queue is full!\n");
return;
}
q->rear = (q->rear + 1) % CAPACITY;
q->items[q->rear] = value;
q->size++;
}
int dequeue(Queue *q) {
if (isEmpty(q)) {
printf("Queue is empty!\n");
return -1;
}
int value = q->items[q->front];
q->front = (q->front + 1) % CAPACITY;
q->size--;
return value;
}
int main() {
Queue q;
initQueue(&q);
enqueue(&q, 10);
enqueue(&q, 20);
enqueue(&q, 30);
printf("Dequeued: %d\n", dequeue(&q)); // 10
printf("Dequeued: %d\n", dequeue(&q)); // 20
enqueue(&q, 40);
enqueue(&q, 50);
enqueue(&q, 60); // 会触发队列满
return 0;
}
非线性结构
5 树
树是分层的数据结构,由节点和边组成。
- 二叉树:每个节点最多有两个子节点(左子节点和右子节点)。
- 二叉搜索树:一种特殊的二叉树,对于任意节点,其左子树的所有节点值都小于该节点,其右子树的所有节点值都大于该节点。
- C 语言实现:二叉搜索树
#include <stdio.h>
#include <stdlib.h>
typedef struct TreeNode {
int data;
struct TreeNode *left;
struct TreeNode *right;
} TreeNode;
TreeNode* createNode(int data) {
TreeNode *node = (TreeNode *)malloc(sizeof(TreeNode));
node->data = data;
node->left = node->right = NULL;
return node;
}
TreeNode* insert(TreeNode *root, int data) {
if (root == NULL) {
return createNode(data);
}
if (data < root->data) {
root->left = insert(root->left, data);
} else if (data > root->data) {
root->right = insert(root->right, data);
}
return root;
}
// 中序遍历 (左-根-右),结果是有序的
void inorderTraversal(TreeNode *root) {
if (root != NULL) {
inorderTraversal(root->left);
printf("%d ", root->data);
inorderTraversal(root->right);
}
}
void freeTree(TreeNode *root) {
if (root != NULL) {
freeTree(root->left);
freeTree(root->right);
free(root);
}
}
int main() {
TreeNode *root = NULL;
root = insert(root, 50);
insert(root, 30);
insert(root, 70);
insert(root, 20);
insert(root, 40);
insert(root, 60);
insert(root, 80);
printf("Inorder traversal: ");
inorderTraversal(root); // 输出: 20 30 40 50 60 70 80
printf("\n");
freeTree(root);
return 0;
}
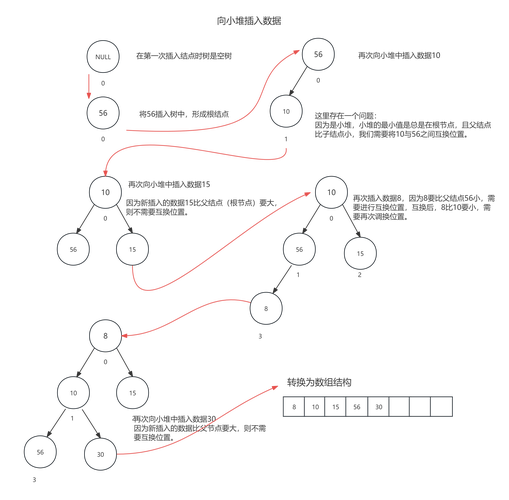
6 堆
堆是一种特殊的完全二叉树,分为最大堆和最小堆。
- 最大堆:任意节点的值都大于或等于其子节点的值。
- 最小堆:任意节点的值都小于或等于其子节点的值。
- 应用:优先队列、堆排序。
- C 语言实现:最大堆
#include <stdio.h>
#include <stdlib.h>
void swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
// 将元素 i 向下调整,使其满足最大堆性质
void heapify(int arr[], int n, int i) {
int largest = i; // 初始化最大元素为根
int left = 2 * i + 1; // 左子节点
int right = 2 * i + 2; // 右子节点
if (left < n && arr[left] > arr[largest]) {
largest = left;
}
if (right < n && arr[right] > arr[largest]) {
largest = right;
}
// 如果最大值不是根,交换并继续调整受影响的子树
if (largest != i) {
swap(&arr[i], &arr[largest]);
heapify(arr, n, largest);
}
}
// 构建最大堆
void buildMaxHeap(int arr[], int n) {
// 从最后一个非叶子节点开始,自底向上构建堆
for (int i = n / 2 - 1; i >= 0; i--) {
heapify(arr, n, i);
}
}
int main() {
int arr[] = {12, 11, 13, 5, 6, 7};
int n = sizeof(arr) / sizeof(arr[0]);
printf("Original array: ");
for (int i = 0; i < n; i++) {
printf("%d ", arr[i]);
}
printf("\n");
buildMaxHeap(arr, n);
printf("Max-heap array: ");
for (int i = 0; i < n; i++) {
printf("%d ", arr[i]);
}
printf("\n");
return 0;
}
7 图
图由顶点和边组成,用于表示多对多的关系。
- 表示方法:
- 邻接矩阵:用一个二维数组表示,
matrix[i][j] = 1表示顶点i和j之间有边,适合稠密图。 - 邻接表:用一个数组或链表数组表示,每个顶点对应一个链表,存储其所有邻接点,适合稀疏图。
- 邻接矩阵:用一个二维数组表示,
- C 语言实现:邻接表
#include <stdio.h>
#include <stdlib.h>
// 邻接表中的节点
typedef struct AdjListNode {
int dest;
struct AdjListNode *next;
} AdjListNode;
// 邻接表
typedef struct AdjList {
AdjListNode *head;
} AdjList;
// 图结构
typedef struct Graph {
int V; // 顶点数
AdjList *array; // 邻接表数组
} Graph;
// 创建新的邻接表节点
AdjListNode* newAdjListNode(int dest) {
AdjListNode *newNode = (AdjListNode *)malloc(sizeof(AdjListNode));
newNode->dest = dest;
newNode->next = NULL;
return newNode;
}
// 创建一个包含 V 个顶点的图
Graph* createGraph(int V) {
Graph *graph = (Graph *)malloc(sizeof(Graph));
graph->V = V;
graph->array = (AdjList *)malloc(V * sizeof(AdjList));
for (int i = 0; i < V; ++i) {
graph->array[i].head = NULL;
}
return graph;
}
// 添加一条边到无向图
void addEdge(Graph *graph, int src, int dest) {
// 添加从 src 到 dest 的边
AdjListNode *newNode = newAdjListNode(dest);
newNode->next = graph->array[src].head;
graph->array[src].head = newNode;
// 因为是无向图,所以也要添加从 dest 到 src 的边
newNode = newAdjListNode(src);
newNode->next = graph->array[dest].head;
graph->array[dest].head = newNode;
}
// 打印图的邻接表表示
void printGraph(Graph *graph) {
for (int v = 0; v < graph->V; ++v) {
AdjListNode *pCrawl = graph->array[v].head;
printf("\n Adjacency list of vertex %d\n head ", v);
while (pCrawl) {
printf("-> %d", pCrawl->dest);
pCrawl = pCrawl->next;
}
printf("\n");
}
}
void freeGraph(Graph *graph) {
for (int v = 0; v < graph->V; v++) {
AdjListNode *current = graph->array[v].head;
while (current != NULL) {
AdjListNode *temp = current;
current = current->next;
free(temp);
}
}
free(graph->array);
free(graph);
}
int main() {
int V = 5;
Graph *graph = createGraph(V);
addEdge(graph, 0, 1);
addEdge(graph, 0, 4);
addEdge(graph, 1, 2);
addEdge(graph, 1, 3);
addEdge(graph, 1, 4);
addEdge(graph, 2, 3);
addEdge(graph, 3, 4);
printGraph(graph);
freeGraph(graph);
return 0;
}
算法
1 排序算法
快速排序
- 思想:分治法,选择一个“基准”元素,将数组分为两部分,一部分小于基准,一部分大于基准,然后递归地对这两部分进行排序。
- 时间复杂度:平均 O(n log n),最坏 O(n²)。
- C 语言实现
#include <stdio.h>
// 交换两个元素
void swap(int* a, int* b) {
int t = *a;
*a = *b;
*b = t;
}
// 分区函数,返回基准元素的最终位置
int partition(int arr[], int low, int high) {
int pivot = arr[high]; // 选择最后一个元素作为基准
int i = (low - 1); // i 是小于基准的区域的边界
for (int j = low; j <= high - 1; j++) {
// 如果当前元素小于或等于基准
if (arr[j] <= pivot) {
i++; // 扩展小于基准的区域
swap(&arr[i], &arr[j]);
}
}
swap(&arr[i + 1], &arr[high]); // 将基准放到正确的位置
return (i + 1);
}
// 快速排序主函数
void quickSort(int arr[], int low, int high) {
if (low < high) {
// pi 是分区后基准的位置
int pi = partition(arr, low, high);
// 递归排序分区
quickSort(arr, low, pi - 1);
quickSort(arr, pi + 1, high);
}
}
// 打印数组
void printArray(int arr[], int size) {
for (int i = 0; i < size; i++) {
printf("%d ", arr[i]);
}
printf("\n");
}
int main() {
int arr[] = {10, 7, 8, 9, 1, 5};
int n = sizeof(arr) / sizeof(arr[0]);
quickSort(arr, 0, n - 1);
printf("Sorted array: \n");
printArray(arr, n);
return 0;
}
2 查找算法
二分查找
- 思想:在有序数组中,通过不断将查找区间减半来快速定位目标值。
- 时间复杂度:O(log n)。
- C 语言实现
#include <stdio.h>
int binarySearch(int arr[], int l, int r, int x) {
while (l <= r) {
int m = l + (r - l) / 2;
// 检查 x 是否在中间位置
if (arr[m] == x) {
return m;
}
// x 更大,则它只能在右半部分
if (arr[m] < x) {
l = m + 1;
}
// x 更小,则它只能在左半部分
else {
r = m - 1;
}
}
// 如果元素不存在
return -1;
}
int main() {
int arr[] = {2, 3, 4, 10, 40};
int n = sizeof(arr) / sizeof(arr[0]);
int x = 10;
int result = binarySearch(arr, 0, n - 1, x);
(result == -1) ? printf("Element is not present in array")
: printf("Element is present at index %d", result);
return 0;
}
3 图算法
深度优先搜索
- 思想:从起始顶点出发,沿着一条路径尽可能深地访问,直到无法继续为止,然后回溯,访问下一条路径。
- 应用:拓扑排序、寻找连通分量、解决迷宫问题。
- C 语言实现 (基于上面的邻接表图)
#include <stdio.h>
#include <stdlib.h>
#include "graph.h" // 假设上面的图结构定义在 graph.h 中
// DFS 辅助函数
void DFSUtil(Graph *graph, int v, bool *visited) {
// 标记当前节点为已访问,并打印
visited[v] = true;
printf("%d ", v);
// 递归访问所有未访问的邻接节点
AdjListNode *pCrawl = graph->array[v].head;
while (pCrawl != NULL) {
if (!visited[pCrawl->dest]) {
DFSUtil(graph, pCrawl->dest, visited);
}
pCrawl = pCrawl->next;
}
}
// DFS 主函数
void DFS(Graph *graph, int startVertex) {
// 创建一个 visited 数组并初始化为 false
bool *visited = (bool *)malloc(graph->V * sizeof(bool));
for (int i = 0; i < graph->V; i++) {
visited[i] = false;
}
// 调用递归辅助函数
DFSUtil(graph, startVertex, visited);
free(visited);
}
// ... (main 函数可以创建图并调用 DFS)
广度优先搜索
- 思想:从起始顶点出发,先访问其所有直接邻接点,然后再按顺序访问这些邻接点的邻接点,一层层向外扩展。
- 应用:最短路径(无权图)、寻找最短连接。
- C 语言实现 (需要用到队列)
#include <stdio.h>
#include <stdlib.h>
#include "graph.h" // 假设上面的图结构定义在 graph.h 中
#include "queue.h" // 假设上面的队列结构定义在 queue.h 中
void BFS(Graph *graph, int startVertex) {
bool *visited = (bool *)malloc(graph->V * sizeof(bool));
for (int i = 0; i < graph->V; i++) {
visited[i] = false;
}
Queue q;
initQueue(&q);
// 访问起始节点并将其入队
visited[startVertex] = true;
enqueue(&q, startVertex);
while (!isEmpty(&q)) {
// 出队一个顶点并打印
int currentVertex = dequeue(&q);
printf("%d ", currentVertex);
// 获取所有邻接点
AdjListNode *pCrawl = graph->array[currentVertex].head;
while (pCrawl != NULL) {
int adjVertex = pCrawl->dest;
if (!visited[adjVertex]) {
visited[adjVertex] = true;
enqueue(&q, adjVertex);
}
pCrawl = pCrawl->next;
}
}
free(visited);
}
学习建议与实践项目
- 从基础开始:确保你对 C 语言的指针和结构体有扎实的理解,这是实现所有数据结构的前提。
- 先理解,再编码:在学习每个数据结构或算法时,先理解其思想、特点和适用场景,可以画图来帮助理解。
- 亲手实现:不要只看不练,将上面的代码敲一遍,尝试修改、扩展它们,为链表添加删除和查找功能;为 BST 删除节点。
- 分析复杂度:对于你实现的每个算法,都要能分析其时间复杂度和空间复杂度,这是衡量算法优劣的关键。
- 调试与测试:学会使用 GDB 等调试工具来跟踪你的程序,编写测试用例来验证你的代码在各种情况下的正确性(边界条件、正常情况、异常情况)。
- 实践项目:
- 命令行通讯录:使用动态数组或链表实现,支持添加、删除、查找、显示联系人。
- 简单的计算器:使用栈来实现表达式求值(后缀表达式)。
- 文件系统模拟:使用树结构来模拟目录和文件的组织形式。
- 路径查找游戏:使用图和 BFS/DFS 算法来实现一个简单的迷宫寻路或地铁线路查询。
- 实现一个
sort函数库:将各种排序算法封装成一个库,可以接受一个函数指针作为参数,用于自定义比较规则。
通过这样的系统学习和实践,你不仅能掌握 C 语言,更能建立起坚实的算法与数据结构功底,这将是你未来从事软件开发工作的宝贵财富,祝你学习顺利!

(图片来源网络,侵删)


