- 线性表
- 顺序表 (动态数组)
- 链表 (单链表)
- 栈
- 顺序栈 (基于数组实现)
- 链栈 (基于链表实现)
- 队列
- 循环队列 (基于数组实现)
- 链队列 (基于链表实现)
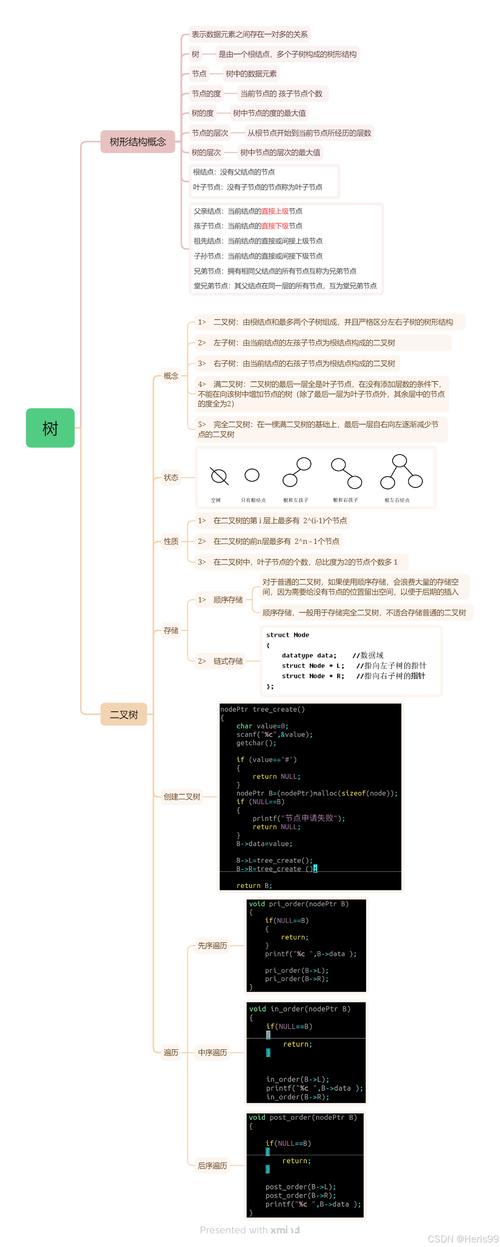
- 树
- 二叉树 (二叉链表存储)
- 二叉搜索树
- 图
- 邻接矩阵
- 邻接表
- 查找
- 顺序查找
- 二分查找
- 排序
- 冒泡排序
- 选择排序
- 插入排序
- 快速排序
- 归并排序
线性表
1 顺序表 (动态数组)
顺序表是用一段地址连续的存储单元依次存储数据元素的线性结构。
(图片来源网络,侵删)
特点:
- 随机访问速度快 (O(1))。
- 插入和删除元素需要移动大量元素,效率较低 (O(n))。
- 大小可以动态调整。
// SeqList.c
#include <stdio.h>
#include <stdlib.h>
#define DEFAULT_CAPACITY 10
// 定义顺序表结构
typedef struct {
int *data; // 动态数组指针
int size; // 当前元素个数
int capacity; // 数组总容量
} SeqList;
// 初始化顺序表
void InitList(SeqList *L) {
L->data = (int *)malloc(DEFAULT_CAPACITY * sizeof(int));
if (!L->data) {
printf("内存分配失败!\n");
exit(1);
}
L->size = 0;
L->capacity = DEFAULT_CAPACITY;
}
// 检查并扩容
void CheckCapacity(SeqList *L) {
if (L->size == L->capacity) {
L->capacity *= 2;
L->data = (int *)realloc(L->data, L->capacity * sizeof(int));
if (!L->data) {
printf("内存重新分配失败!\n");
exit(1);
}
printf("顺序表已扩容,新容量为: %d\n", L->capacity);
}
}
// 在位置 i 插入元素 e (从0开始)
int InsertElem(SeqList *L, int i, int e) {
if (i < 0 || i > L->size) {
printf("插入位置不合法!\n");
return 0;
}
CheckCapacity(L);
// 从后往前移动元素,为新元素腾出空间
for (int j = L->size; j > i; j--) {
L->data[j] = L->data[j - 1];
}
L->data[i] = e;
L->size++;
return 1;
}
// 删除位置 i 的元素,并用 e 返回其值
int DeleteElem(SeqList *L, int i, int *e) {
if (i < 0 || i >= L->size) {
printf("删除位置不合法!\n");
return 0;
}
*e = L->data[i];
// 从前往后移动元素,覆盖被删除的元素
for (int j = i; j < L->size - 1; j++) {
L->data[j] = L->data[j + 1];
}
L->size--;
return 1;
}
// 获取位置 i 的元素
int GetElem(SeqList *L, int i, int *e) {
if (i < 0 || i >= L->size) {
printf("获取位置不合法!\n");
return 0;
}
*e = L->data[i];
return 1;
}
// 打印顺序表
void PrintList(SeqList *L) {
printf("顺序表内容: [");
for (int i = 0; i < L->size; i++) {
printf("%d", L->data[i]);
if (i < L->size - 1) {
printf(", ");
}
}
printf("]\n");
}
// 销毁顺序表,释放内存
void DestroyList(SeqList *L) {
free(L->data);
L->data = NULL;
L->size = 0;
L->capacity = 0;
}
// 测试代码
int main() {
SeqList list;
InitList(&list);
InsertElem(&list, 0, 10);
InsertElem(&list, 1, 20);
InsertElem(&list, 2, 30);
PrintList(&list); // [10, 20, 30]
InsertElem(&list, 1, 15); // 在位置1插入15
PrintList(&list); // [10, 15, 20, 30]
int deleted_val;
DeleteElem(&list, 2, &deleted_val); // 删除位置2的元素
printf("删除的元素是: %d\n", deleted_val);
PrintList(&list); // [10, 15, 30]
int get_val;
GetElem(&list, 1, &get_val);
printf("位置1的元素是: %d\n", get_val); // 15
DestroyList(&list);
return 0;
}
2 链表 (单链表)
链表是通过节点中的指针链接在一起的非连续存储的线性结构。
特点:
- 插入和删除元素效率高 (O(1),已知节点位置时)。
- 不需要预先分配空间,内存利用率高。
- 随机访问速度慢 (O(n))。
// LinkedList.c
#include <stdio.h>
#include <stdlib.h>
// 定义链表节点
typedef struct Node {
int data;
struct Node *next;
} Node;
// 定义链表结构 (带头结点)
typedef struct {
Node *head; // 头结点,不存储数据,指向第一个实际数据节点
int length;
} LinkedList;
// 初始化链表
void InitList(LinkedList *L) {
L->head = (Node *)malloc(sizeof(Node));
if (!L->head) {
printf("内存分配失败!\n");
exit(1);
}
L->head->next = NULL; // 头结点的next指向NULL,表示空链表
L->length = 0;
}
// 在位置 i 插入元素 e (从0开始)
int InsertElem(LinkedList *L, int i, int e) {
if (i < 0 || i > L->length) {
printf("插入位置不合法!\n");
return 0;
}
Node *p = L->head; // p从头结点开始
// 找到第 i-1 个节点
for (int j = 0; j < i; j++) {
p = p->next;
}
// 创建新节点
Node *new_node = (Node *)malloc(sizeof(Node));
if (!new_node) {
printf("内存分配失败!\n");
return 0;
}
new_node->data = e;
// 插入操作
new_node->next = p->next;
p->next = new_node;
L->length++;
return 1;
}
// 删除位置 i 的元素,并用 e 返回其值
int DeleteElem(LinkedList *L, int i, int *e) {
if (i < 0 || i >= L->length) {
printf("删除位置不合法!\n");
return 0;
}
Node *p = L->head;
// 找到第 i-1 个节点
for (int j = 0; j < i; j++) {
p = p->next;
}
Node *q = p->next; // q是要删除的节点
*e = q->data;
p->next = q->next; // 前驱节点指向后继节点
free(q); // 释放被删除节点的内存
L->length--;
return 1;
}
// 打印链表
void PrintList(LinkedList *L) {
printf("链表内容: [");
Node *p = L->head->next; // 从第一个实际数据节点开始
while (p != NULL) {
printf("%d", p->data);
p = p->next;
if (p != NULL) {
printf(", ");
}
}
printf("]\n");
}
// 销毁链表
void DestroyList(LinkedList *L) {
Node *p = L->head;
Node *q;
while (p != NULL) {
q = p;
p = p->next;
free(q);
}
L->head = NULL;
L->length = 0;
}
// 测试代码
int main() {
LinkedList list;
InitList(&list);
InsertElem(&list, 0, 10);
InsertElem(&list, 1, 20);
InsertElem(&list, 2, 30);
PrintList(&list); // [10, 20, 30]
InsertElem(&list, 1, 15); // 在位置1插入15
PrintList(&list); // [10, 15, 20, 30]
int deleted_val;
DeleteElem(&list, 2, &deleted_val); // 删除位置2的元素
printf("删除的元素是: %d\n", deleted_val);
PrintList(&list); // [10, 15, 30]
DestroyList(&list);
return 0;
}
栈
栈是一种特殊的线性表,只允许在一端进行插入和删除操作,遵循 后进先出 的原则。
(图片来源网络,侵删)
1 顺序栈
// SeqStack.c
#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZE 100
typedef struct {
int data[MAX_SIZE];
int top; // 栈顶指针
} SeqStack;
void InitStack(SeqStack *S) {
S->top = -1;
}
int IsEmpty(SeqStack *S) {
return S->top == -1;
}
int IsFull(SeqStack *S) {
return S->top == MAX_SIZE - 1;
}
int Push(SeqStack *S, int e) {
if (IsFull(S)) {
printf("栈已满,无法压栈!\n");
return 0;
}
S->data[++S->top] = e;
return 1;
}
int Pop(SeqStack *S, int *e) {
if (IsEmpty(S)) {
printf("栈为空,无法出栈!\n");
return 0;
}
*e = S->data[S->top--];
return 1;
}
void PrintStack(SeqStack *S) {
printf("栈内容 (从底到顶): [");
for (int i = 0; i <= S->top; i++) {
printf("%d", S->data[i]);
if (i < S->top) printf(", ");
}
printf("]\n");
}
int main() {
SeqStack S;
InitStack(&S);
Push(&S, 10);
Push(&S, 20);
Push(&S, 30);
PrintStack(&S); // [10, 20, 30]
int val;
Pop(&S, &val);
printf("出栈元素: %d\n", val); // 30
PrintStack(&S); // [10, 20]
return 0;
}
队列
队列也是一种特殊的线性表,只允许在一端插入,在另一端删除,遵循 先进先出 的原则。
1 循环队列
为了避免顺序队列的“假溢出”现象(头指针和尾指针都向后移动,但队列中还有空间),将存储空间想象成一个环。
// CircularQueue.c
#include <stdio.h>
#include <stdlib.h>
#define MAX_SIZE 6
typedef struct {
int data[MAX_SIZE];
int front; // 队头指针
int rear; // 队尾指针
} CircularQueue;
void InitQueue(CircularQueue *Q) {
Q->front = Q->rear = 0;
}
int IsEmpty(CircularQueue *Q) {
return Q->front == Q->rear;
}
// 注意:循环队列满的条件是 (rear + 1) % MAX_SIZE == front
int IsFull(CircularQueue *Q) {
return (Q->rear + 1) % MAX_SIZE == Q->front;
}
int EnQueue(CircularQueue *Q, int e) {
if (IsFull(Q)) {
printf("队列已满,无法入队!\n");
return 0;
}
Q->data[Q->rear] = e;
Q->rear = (Q->rear + 1) % MAX_SIZE;
return 1;
}
int DeQueue(CircularQueue *Q, int *e) {
if (IsEmpty(Q)) {
printf("队列为空,无法出队!\n");
return 0;
}
*e = Q->data[Q->front];
Q->front = (Q->front + 1) % MAX_SIZE;
return 1;
}
void PrintQueue(CircularQueue *Q) {
printf("队列内容: [");
int i = Q->front;
while (i != Q->rear) {
printf("%d", Q->data[i]);
i = (i + 1) % MAX_SIZE;
if (i != Q->rear) printf(", ");
}
printf("]\n");
}
int main() {
CircularQueue Q;
InitQueue(&Q);
EnQueue(&Q, 1);
EnQueue(&Q, 2);
EnQueue(&Q, 3);
PrintQueue(&Q); // [1, 2, 3]
int val;
DeQueue(&Q, &val);
printf("出队元素: %d\n", val); // 1
PrintQueue(&Q); // [2, 3]
return 0;
}
树
1 二叉树
// BinaryTree.c
#include <stdio.h>
#include <stdlib.h>
// 定义二叉树节点
typedef struct BTNode {
char data;
struct BTNode *lchild;
struct BTNode *rchild;
} BTNode;
// 创建二叉树 (按前序遍历顺序输入,用 '#' 表示空节点)
BTNode* CreateBTree() {
char ch;
scanf("%c", &ch);
if (ch == '#') {
return NULL;
}
BTNode *root = (BTNode *)malloc(sizeof(BTNode));
root->data = ch;
printf("请输入 %c 的左子节点: ", ch);
root->lchild = CreateBTree();
printf("请输入 %c 的右子节点: ", ch);
root->rchild = CreateBTree();
return root;
}
// 前序遍历
void PreOrder(BTNode *root) {
if (root == NULL) return;
printf("%c ", root->data);
PreOrder(root->lchild);
PreOrder(root->rchild);
}
// 中序遍历
void InOrder(BTNode *root) {
if (root == NULL) return;
InOrder(root->lchild);
printf("%c ", root->data);
InOrder(root->rchild);
}
// 后序遍历
void PostOrder(BTNode *root) {
if (root == NULL) return;
PostOrder(root->lchild);
PostOrder(root->rchild);
printf("%c ", root->data);
}
// 释放二叉树内存
void DestroyBTree(BTNode *root) {
if (root == NULL) return;
DestroyBTree(root->lchild);
DestroyBTree(root->rchild);
free(root);
}
int main() {
printf("请输入根节点: ");
BTNode *root = CreateBTree();
printf("前序遍历结果: ");
PreOrder(root);
printf("\n");
printf("中序遍历结果: ");
InOrder(root);
printf("\n");
printf("后序遍历结果: ");
PostOrder(root);
printf("\n");
DestroyBTree(root);
return 0;
}
2 二叉搜索树
二叉搜索树是一种特殊的二叉树,其左子树所有节点值小于根节点,右子树所有节点值大于根节点。
// BinarySearchTree.c
#include <stdio.h>
#include <stdlib.h>
typedef struct BSTNode {
int data;
struct BSTNode *left;
struct BSTNode *right;
} BSTNode;
// 查找
BSTNode* Search(BSTNode *root, int key) {
if (root == NULL || root->data == key) {
return root;
}
if (key < root->data) {
return Search(root->left, key);
} else {
return Search(root->right, key);
}
}
// 插入
BSTNode* Insert(BSTNode *root, int key) {
if (root == NULL) {
BSTNode *new_node = (BSTNode *)malloc(sizeof(BSTNode));
new_node->data = key;
new_node->left = new_node->right = NULL;
return new_node;
}
if (key < root->data) {
root->left = Insert(root->left, key);
} else if (key > root->data) {
root->right = Insert(root->right, key);
}
// 如果key已存在,则不做任何操作
return root;
}
// 找到最小节点 (用于删除)
BSTNode* FindMin(BSTNode *root) {
while (root->left != NULL) {
root = root->left;
}
return root;
}
// 删除
BSTNode* Delete(BSTNode *root, int key) {
if (root == NULL) return NULL;
if (key < root->data) {
root->left = Delete(root->left, key);
} else if (key > root->data) {
root->right = Delete(root->right, key);
} else {
// 找到了要删除的节点
// 情况1: 节点只有一个子节点或没有子节点
if (root->left == NULL) {
BSTNode *temp = root->right;
free(root);
return temp;
} else if (root->right == NULL) {
BSTNode *temp = root->left;
free(root);
return temp;
}
// 情况2: 节点有两个子节点
// 找到右子树中的最小节点(或左子树中的最大节点)
BSTNode *temp = FindMin(root->right);
// 将该节点的值复制到当前节点
root->data = temp->data;
// 删除右子树中的那个最小节点
root->right = Delete(root->right, temp->data);
}
return root;
}
// 中序遍历 (输出有序序列)
void InOrderTraversal(BSTNode *root) {
if (root != NULL) {
InOrderTraversal(root->left);
printf("%d ", root->data);
InOrderTraversal(root->right);
}
}
void FreeTree(BSTNode *root) {
if (root == NULL) return;
FreeTree(root->left);
FreeTree(root->right);
free(root);
}
int main() {
BSTNode *root = NULL;
root = Insert(root, 50);
root = Insert(root, 30);
root = Insert(root, 70);
root = Insert(root, 20);
root = Insert(root, 40);
root = Insert(root, 60);
root = Insert(root, 80);
printf("中序遍历 (BST 应是有序的): ");
InOrderTraversal(root); // 20 30 40 50 60 70 80
printf("\n");
printf("查找 40: %s\n", Search(root, 40) ? "找到" : "未找到");
printf("查找 90: %s\n", Search(root, 90) ? "找到" : "未找到");
printf("删除 20...\n");
root = Delete(root, 20);
printf("删除后的中序遍历: ");
InOrderTraversal(root); // 30 40 50 60 70 80
printf("\n");
FreeTree(root);
return 0;
}
图
图由顶点和边组成,是网状结构。
(图片来源网络,侵删)
1 邻接矩阵
用二维数组表示顶点之间的连接关系,适合稠密图。
// AdjacencyMatrix.c
#include <stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#define MAX_VERTICES 100
typedef struct {
char vertices[MAX_VERTICES]; // 顶点信息
int edges[MAX_VERTICES][MAX_VERTICES]; // 邻接矩阵
int numVertices; // 当前顶点数
bool isDirected; // 是否为有向图
} Graph;
void InitGraph(Graph *G, bool isDirected) {
G->numVertices = 0;
G->isDirected = isDirected;
for (int i = 0; i < MAX_VERTICES; i++) {
G->vertices[i] = '\0';
for (int j = 0; j < MAX_VERTICES; j++) {
G->edges[i][j] = 0; // 0 表示无边
}
}
}
void AddVertex(Graph *G, char vertex) {
if (G->numVertices >= MAX_VERTICES) {
printf("顶点数量已达上限!\n");
return;
}
G->vertices[G->numVertices] = vertex;
G->numVertices++;
}
void AddEdge(Graph *G, char v1, char v2) {
int i = -1, j = -1;
for (int k = 0; k < G->numVertices; k++) {
if (G->vertices[k] == v1) i = k;
if (G->vertices[k] == v2) j = k;
}
if (i == -1 || j == -1) {
printf("顶点不存在!\n");
return;
}
G->edges[i][j] = 1;
if (!G->isDirected) {
G->edges[j][i] = 1;
}
}
void PrintGraph(Graph *G) {
printf(" ");
for (int i = 0; i < G->numVertices; i++) {
printf("%c ", G->vertices[i]);
}
printf("\n");
for (int i = 0; i < G->numVertices; i++) {
printf("%c ", G->vertices[i]);
for (int j = 0; j < G->numVertices; j++) {
printf("%d ", G->edges[i][j]);
}
printf("\n");
}
}
int main() {
Graph G;
InitGraph(&G, false); // 创建一个无向图
AddVertex(&G, 'A');
AddVertex(&G, 'B');
AddVertex(&G, 'C');
AddVertex(&G, 'D');
AddEdge(&G, 'A', 'B');
AddEdge(&G, 'A', 'C');
AddEdge(&G, 'B', 'D');
AddEdge(&G, 'C', 'D');
PrintGraph(&G);
return 0;
}
2 邻接表
用链表数组表示每个顶点的邻接点,适合稀疏图。
// AdjacencyList.c
#include <stdio.h>
#include <stdlib.h>
#define MAX_VERTICES 100
// 定义邻接表节点
typedef struct AdjListNode {
int dest; // 邻接点在顶点数组中的索引
struct AdjListNode *next;
} AdjListNode;
// 定义顶点
typedef struct AdjList {
char vertex; // 顶点信息
AdjListNode *head; // 指向邻接表头节点
} AdjList;
// 定义图
typedef struct {
AdjList *array; // 顶点数组
int numVertices; // 当前顶点数
bool isDirected; // 是否为有向图
} Graph;
// 创建邻接表节点
AdjListNode* NewAdjListNode(int dest) {
AdjListNode *new_node = (AdjListNode*)malloc(sizeof(AdjListNode));
new_node->dest = dest;
new_node->next = NULL;
return new_node;
}
// 初始化图
void InitGraph(Graph *G, bool isDirected) {
G->numVertices = 0;
G->isDirected = isDirected;
G->array = (AdjList*)malloc(MAX_VERTICES * sizeof(AdjList));
for (int i = 0; i < MAX_VERTICES; i++) {
G->array[i].head = NULL;
}
}
// 添加顶点
void AddVertex(Graph *G, char vertex) {
if (G->numVertices >= MAX_VERTICES) {
printf("顶点数量已达上限!\n");
return;
}
G->array[G->numVertices].vertex = vertex;
G->array[G->numVertices].head = NULL;
G->numVertices++;
}
// 添加边
void AddEdge(Graph *G, char v1, char v2) {
int i = -1, j = -1;
for (int k = 0; k < G->numVertices; k++) {
if (G->array[k].vertex == v1) i = k;
if (G->array[k].vertex == v2) j = k;
}
if (i == -1 || j == -1) {
printf("顶点不存在!\n");
return;
}
// 添加 v2 到 v1 的邻接表
AdjListNode *new_node = NewAdjListNode(j);
new_node->next = G->array[i].head;
G->array[i].head = new_node;
// 如果是无向图,添加 v1 到 v2 的邻接表
if (!G->isDirected) {
new_node = NewAdjListNode(i);
new_node->next = G->array[j].head;
G->array[j].head = new_node;
}
}
// 打印图
void PrintGraph(Graph *G) {
for (int i = 0; i < G->numVertices; i++) {
printf("顶点 %c 的邻接点: ", G->array[i].vertex);
AdjListNode *p = G->array[i].head;
while (p) {
printf("%c ", G->array[p->dest].vertex);
p = p->next;
}
printf("\n");
}
}
// 释放邻接表内存
void FreeGraph(Graph *G) {
for (int i = 0; i < G->numVertices; i++) {
AdjListNode *p = G->array[i].head;
while (p) {
AdjListNode *temp = p;
p = p->next;
free(temp);
}
}
free(G->array);
}
int main() {
Graph G;
InitGraph(&G, false); // 创建一个无向图
AddVertex(&G, 'A');
AddVertex(&G, 'B');
AddVertex(&G, 'C');
AddVertex(&G, 'D');
AddEdge(&G, 'A', 'B');
AddEdge(&G, 'A', 'C');
AddEdge(&G, 'B', 'D');
AddEdge(&G, 'C', 'D');
PrintGraph(&G);
FreeGraph(&G);
return 0;
}
查找
1 顺序查找
最简单的查找方法,从头到尾依次比较。
// SequentialSearch.c
int SequentialSearch(int arr[], int n, int key) {
for (int i = 0; i < n; i++) {
if (arr[i] == key) {
return i; // 返回找到的位置
}
}
return -1; // 未找到
}
2 二分查找
要求数组必须是有序的,每次查找都将查找范围缩小一半。
// BinarySearch.c
int BinarySearch(int arr[], int n, int key) {
int low = 0;
int high = n - 1;
while (low <= high) {
int mid = low + (high - low) / 2; // 防止溢出
if (arr[mid] == key) {
return mid;
} else if (arr[mid] < key) {
low = mid + 1;
} else {
high = mid - 1;
}
}
return -1; // 未找到
}
排序
1 冒泡排序
通过多次遍历,每次将最大的元素“冒泡”到数组末尾。
// BubbleSort.c
void BubbleSort(int arr[], int n) {
for (int i = 0; i < n - 1; i++) {
bool swapped = false;
for (int j = 0; j < n - 1 - i; j++) {
if (arr[j] > arr[j + 1]) {
// 交换
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
swapped = true;
}
}
// 如果某一轮没有发生交换,说明数组已经有序
if (!swapped) break;
}
}
2 快速排序
采用分治法思想,选择一个基准元素,将数组分为两部分,一部分小于基准,一部分大于基准,然后递归地对这两部分进行排序。
// QuickSort.c
// 交换函数
void Swap(int *a, int *b) {
int temp = *a;
*a = *b;
*b = temp;
}
// 分区函数,返回基准元素的最终位置
int Partition(int arr[], int low, int high) {
int pivot = arr[high]; // 选择最后一个元素作为基准
int i = low - 1; // i 是小于基准的区域的边界
for (int j = low; j < high; j++) {
if (arr[j] < pivot) {
i++;
Swap(&arr[i], &arr[j]);
}
}
Swap(&arr[i + 1], &arr[high]); // 将基准放到正确的位置
return i + 1;
}
// 快速排序主函数
void QuickSort(int arr[], int low, int high) {
if (low < high) {
int pi = Partition(arr, low, high); // pi 是分区点
QuickSort(arr, low, pi - 1); // 递归排序左半部分
QuickSort(arr, pi + 1, high); // 递归排序右半部分
}
}
3 归并排序
采用分治法思想,先递归地将数组分成两半,直到每个子数组只有一个元素,然后将这些有序的子数组合并成一个大的有序数组。
// MergeSort.c
// 合并两个有序子数组
void Merge(int arr[], int l, int m, int r) {
int i, j, k;
int n1 = m - l + 1;
int n2 = r - m;
// 创建临时数组
int L[n1], R[n2];
// 拷贝数据到临时数组
for (i = 0; i < n1; i++)
L[i] = arr[l + i];
for (j = 0; j < n2; j++)
R[j] = arr[m + 1 + j];
// 合并临时数组
i = 0;
j = 0;
k = l;
while (i < n1 && j < n2) {
if (L[i] <= R[j]) {
arr[k] = L[i];
i++;
} else {
arr[k] = R[j];
j++;
}
k++;
}
// 拷贝剩余元素
while (i < n1) {
arr[k] = L[i];
i++;
k++;
}
while (j < n2) {
arr[k] = R[j];
j++;
k++;
}
}
// 归并排序主函数
void MergeSort(int arr[], int l, int r) {
if (l < r) {
int m = l + (r - l) / 2;
MergeSort(arr, l, m); // 递归排序左半部分
MergeSort(arr, m + 1, r); // 递归排序右半部分
Merge(arr, l, m, r); // 合并
}
}
如何使用这些代码
- 复制粘贴:将您需要的某个数据结构的完整代码块复制到一个
.c文件中(SeqList.c)。 - 编译运行:使用 C 语言编译器(如 GCC)进行编译和运行。
gcc SeqList.c -o seq_list ./seq_list
- 学习和修改:仔细阅读代码中的注释,理解其工作原理,您可以修改
main函数中的测试代码来探索不同操作的效果,或者尝试实现新的功能。
希望这些源代码能对您的学习有所帮助!


