这份指南将从基础概念、配置步骤、高级技巧三个方面,为你提供一份全面且易于理解的 DedeCMS 5.7 采集规则教程。

(图片来源网络,侵删)
基础概念:采集规则由什么组成?
在开始配置之前,你必须理解 DedeCMS 采集规则的几个核心组成部分,它们就像一个“指令清单”,告诉采集器去哪里抓、抓什么、怎么存。
-
目标网址
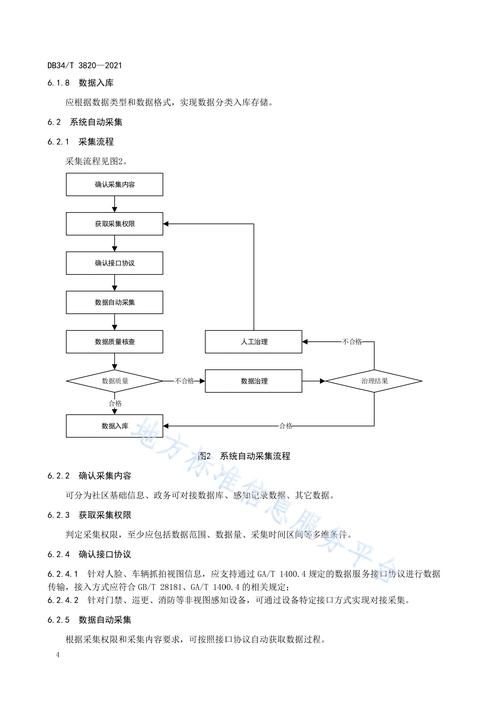
- 作用:定义你要采集的网页列表页,你要采集某个新闻网站的所有文章,列表页就是包含所有文章标题和链接的页面。
- 特点:通常包含分页,
list_1.html,list_2.html等,规则需要能识别这种规律。
-
列表规则
- 作用:从“目标网址”中,精确地提取出每一条具体内容的链接。
- 示例:在列表页源码中,每篇文章的链接可能都在
<li class="news-item">标签内的<a>标签里,列表规则就是要找到这个<li>或<a>。
-
内容规则
 (图片来源网络,侵删)
(图片来源网络,侵删)- 作用:这是最核心的部分,它定义了如何从文章详情页中抓取你需要的信息,如标题、作者、来源、发布时间、正文内容、图片等。
- 组成:
- 内容选择器:通常是一个 XPath 表达式或 CSS 选择器,用于定位正文所在的 HTML 元素。
<div class="article-content">。 - 处理方法:对抓取到的内容进行二次处理,如去除广告、替换特定文本、过滤 HTML 标签等。
- 内容选择器:通常是一个 XPath 表达式或 CSS 选择器,用于定位正文所在的 HTML 元素。
-
分页规则
- 作用:用于抓取列表页的下一页,实现自动化翻页采集。
- 示例:找到“下一页”按钮的链接,然后继续抓取该链接对应的列表页,直到没有下一页为止。
-
发布栏目
- 作用:指定采集到的文章最终要存放在哪个网站栏目下,这是内容归档的关键。
-
发布选项
- 作用:定义采集内容的默认属性,如是否生成 HTML、是否审核、是否推荐等。
配置步骤:手把手教你写采集规则
假设我们要采集一个网站 http://example.com/news/ 下的新闻文章。
(图片来源网络,侵删)
步骤 1:创建并选择采集节点
- 登录 DedeCMS 后台。
- 进入 【采集】 -> 【采集管理】。
- 点击 【增加采集节点】。
- 填写节点基本信息:
- 节点名称:给你的采集任务起个名字,如“XX新闻网”。
- 目标网址:填写列表页的地址,如
http://example.com/news/list_1.html。 - 列表分页:如果你的列表页有分页,选择“有”,并填写列表页的 URL 规律,如
http://example.com/news/list_{page}.html。{page}会被系统自动替换为页码。 - 起始页:从第几页开始采集,通常是
1。 - 截止页:采集到第几页停止,
0表示采集所有页。 - 保存。
步骤 2:配置列表规则
这是找到文章链接的关键一步。
- 在节点列表中,找到你刚创建的节点,点击 【选择】 -> 【修改】。
- 进入节点后,切换到 【高级选项】 -> 【列表页】。
- 列表规则:
- 点击 【获取列表】 按钮,系统会自动加载你设置的“目标网址”。
- 在下方会出现一个可视化区域,左侧是网页源码,右侧是预览效果。
- 用鼠标在左侧的源码中,拖动选中一个包含文章标题和链接的区块,选中
<div class="news-item">...</div>这个完整的区块。 - 系统会自动生成一个列表规则(通常是 XPath 表达式),你可以手动微调它,确保它能准确匹配所有文章项。
- 文章链接:在刚才选中的区块内,用鼠标精确点击文章的
<a>,系统会自动提取出<a>标签的href属性值,这就是文章的真实链接。 - 测试:点击 【测试】 按钮,看是否能正确抓取到当前页的文章列表和链接。
步骤 3:配置内容规则
这是抓取文章具体内容的步骤。
- 在 【高级选项】 中,切换到 页】。
- 标题规则:
- 点击 【浏览】,系统会跳转到刚才抓取到的一篇文章详情页。
- 在详情页源码中,用鼠标选中文章标题,
<h1 class="article-title">...</h1>。 - 系统会自动填充标题规则。
- 内容规则:
- 这是最重要的一步,在详情页源码中,用鼠标从文章正文的最开始,一直拖动到文章正文的最后,选中
<div class="article-content">...</div>这个包含所有正文内容的 div。 - 系统会自动填充内容规则。
- 处理方法规则下方,你可以进行一些高级处理。
- 去除广告:在“过滤”或“处理方法”中,输入广告代码的特定标签或文字,
|<div class="ad">.*?</div>|is。 - 图片处理:勾选 【远程图片本地化】,这样采集到的图片会自动下载到你的服务器,并替换为本地链接,防止失效。
- 内容截取:可以设置只截取正文的前 N 个字符。
- 去除广告:在“过滤”或“处理方法”中,输入广告代码的特定标签或文字,
- 这是最重要的一步,在详情页源码中,用鼠标从文章正文的最开始,一直拖动到文章正文的最后,选中
- 其他字段规则:
- 作者:在详情页找到作者信息所在的标签并选中。
- 来源:找到来源信息所在的标签并选中。
- 发布时间:找到时间信息所在的标签并选中。
- 内容简介:可以手动设置,或者从正文中自动截取一段。
- 测试:点击 【测试】 按钮,检查是否能正确抓取文章的标题、正文、作者等信息。
步骤 4:设置发布选项
- 切换到 【发布栏目】 选项卡。
- 选择栏目:点击下拉菜单,选择你希望文章发布到的网站栏目。必须提前在【栏目管理】中创建好栏目。
- 发布选项:
- 自动审核:勾选后,采集到的文章会直接通过审核并显示在前台,不勾选则文章处于待审核状态。
- 自动生成 HTML:建议勾选,这样文章发布后就是静态页面,有利于 SEO。
- 是否置顶/推荐:根据需要设置。
步骤 5:保存并开始采集
- 点击 【保存】 按钮,完成所有规则配置。
- 返回 【采集管理】 列表页面,找到你的节点,点击 【选择】 -> 【开始采集】。
- 系统会开始执行采集任务,你可以点击 【刷新】 查看采集进度和结果。
高级技巧与常见问题
-
如何处理动态加载(Ajax)的网页?
- DedeCMS 默认不支持直接抓取 Ajax 动态加载的内容,你需要先在浏览器中手动加载完所有内容,然后复制最终的 HTML 源码,粘贴到 DedeCMS 的 【测试网页】 功能中进行规则匹配,或者,找到 Ajax 请求的真实 API 接口,直接采集接口返回的 JSON 或 XML 数据,但这需要更高级的技术。
-
规则匹配失败怎么办?
- 检查选择器:确保你用鼠标选中的 HTML 结构是唯一的、准确的,多检查几个页面,看结构是否一致。
- 使用正则表达式:对于复杂的、不固定的结构,可以在规则中使用正则表达式进行匹配。
发布时间:(.*?)<br>。 - 简化规则:有时候规则太复杂会导致失败,尝试简化选择器,只保留最核心的标签。
-
如何防止重复采集?
DedeCMS 采集器会自动检查文章标题是否已存在于目标栏目中,如果标题完全相同,则不会重复采集,你也可以通过自定义 PHP 脚本,在发布前检查文章的某个唯一标识(如文章 URL 或特定 MD5 值)。
-
采集速度慢怎么办?
- 采集是 CPU 和 I/O 密集型操作,速度慢是正常的。
- 可以适当减少“同时运行任务数”和“每个任务获取间隔”。
- 避免在网站访问高峰期进行大规模采集。
- 如果采集量巨大,可以考虑分时段、分批次进行。
-
图片本地化失败?
- 检查目录权限:确保 DedeCMS 的
uploads目录及其子目录有写入权限(通常是 755 或 777)。 - 检查图片链接:确保图片的 URL 是完整的(以
http://或https://开头)。 - 检查服务器环境:部分虚拟主机或安全设置可能会阻止远程文件下载功能。
- 检查目录权限:确保 DedeCMS 的
DedeCMS 5.7 的采集器功能强大但配置相对繁琐,核心在于耐心和细心。
成功的关键流程: 确定目标 -> 分析网页结构 -> 精准选择列表和内容区块 -> 反复测试 -> 开始采集。
多练习几次,熟悉了 XPath 和 HTML 结构后,你就能快速掌握配置采集规则的方法,极大地提高网站内容更新的效率。


