2025年蓝桥杯C语言省赛B组试题(部分)
第一题:年龄巧合
描述:**
科学家在一张纸上写了一个不正确的等式:2025 - 14 = 2025,显然这个等式是错误的,如果将数字 14 的两个数字 1 和 4 的位置对调,就会得到 41,而这个等式就变成了 2025 - 41 = 1973,这个等式是正确的。

类似地,对于等式 1900 - 95 = 1805,将 95 对调得到 59,等式 1900 - 59 = 1841 也是正确的。
给定一个起始年份 start 和一个结束年份 end,请找出所有在 [start, end] 区间内的年份 Y,使得存在一个两位数 X (即 10 <= X <= 99),满足 Y - X 的结果等于将 X 的十位和个位数字对调后得到的数。
输入格式:
输入为一行,包含两个整数 start 和 end,用空格隔开。
输出格式:
输出所有满足条件的年份 Y,每个年份占一行,年份按从小到大的顺序输出。
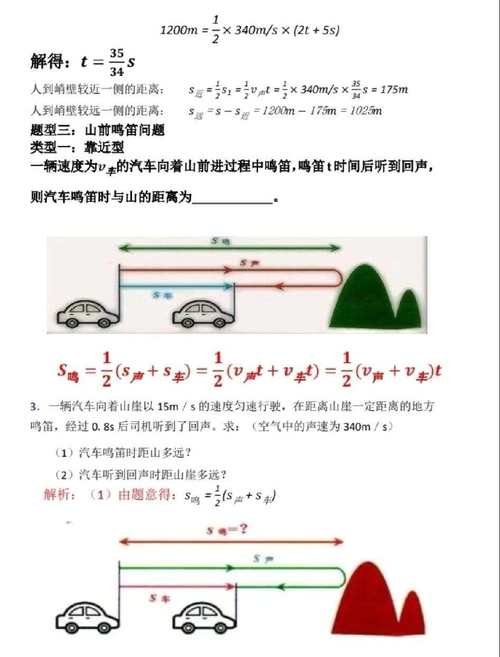
输入样例:
2000 2025
输出样例:
2002
2012
2025解析与思路:
- 理解题意:我们需要遍历从
start到end的每一个年份Y。 - 寻找X:对于每一个年份
Y,我们需要检查是否存在一个两位数X,使得Y - X的结果等于X的数字对调后的数。 - 对调数字:对于一个两位数
X,如何得到它的对调数?可以设X的十位数字为a,个位数字为b,则X = 10 * a + b,对调后的数X' = 10 * b + a。 - 建立等式:根据题意,有
Y - X = X',将X和X'的表达式代入,得到Y - (10*a + b) = 10*b + a。 - 推导关系:整理上式,可以得到
Y = 10*a + b + 10*b + a,即Y = 11*a + 11*b,进一步化简为Y = 11 * (a + b)。 - 寻找规律:这个公式是解题的关键,它告诉我们,满足条件的年份
Y必须是11的倍数,因为a和b是数字(a从1到9,b从0到9),a + b的范围是[1, 18]。Y的可能取值为11 * 1,11 * 2, ...,11 * 18,即11, 22, 33, ..., 198。 - 验证X:找到
Y后,我们可以反向求出X。X = Y - X',但我们也可以直接从Y和a, b的关系来推导。X = 10*a + b,因为Y = 11*(a+b),X的各位数字之和a+b = Y / 11。X = Y - (10*b + a),这个关系有点绕,更简单的方法是:既然Y是11的倍数,我们可以直接计算X的值。X = Y - (10*b + a),而10*b + a = Y - X,这又回到了原点。- 更好的验证方式是:对于一个给定的
Y,我们可以计算出S = Y / 11(因为Y是11的倍数)。S = a + b。X的各位数字之和必须等于S。X必须是一个两位数,Y - X也必须是一个两位数(因为X'是两位数)。 - 让我们重新审视
Y - X = X'。X'是X的对调数,X'也必然是一个两位数,这意味着Y - X必须在[10, 99]之间。 X必须满足Y - 99 <= X <= Y - 10。- 结合
X是两位数 (10 <= X <= 99),X的取值范围是max(10, Y-99)到min(99, Y-10)。 X必须满足Y = 11 * (a+b),这个条件已经通过筛选Y来保证了。
- 更好的验证方式是:对于一个给定的
- 简化算法:根据第6步的结论,我们不需要遍历所有年份,只需要找出
[start, end]区间内所有11的倍数Y,对于每一个这样的Y,我们只需要验证是否存在一个两位数X,使得Y - X是X的对调数。- 我们可以这样验证:遍历所有可能的两位数
X(从10到99),检查Y - X是否等于swap(X),如果存在,则Y是一个解。 - 但这样效率不高,更优的方法是:
X = Y - X',因为X'也是两位数,X的范围是Y-99到Y-10,我们只需要在这个小范围内寻找X即可。 - 最简单的方法是:直接利用
Y = 11 * (a+b)的特性,对于Y,计算S = Y / 11。SX的各位数字之和,然后我们只需要检查是否存在一个两位数X,其各位数字之和为S,Y - X等于X的对调数,这个检查本身有点循环论证。 - 最终的高效思路:既然
Y必须是11的倍数,那么我们直接遍历[start, end]区间内所有11的倍数Y,对于每一个Y,我们遍历所有可能的两位数X(从max(10, Y-99)到min(99, Y-10)),检查Y - X是否等于swap(X),如果找到,就输出Y并跳出内层循环(因为一个Y只需输出一次)。
- 我们可以这样验证:遍历所有可能的两位数
参考代码 (C语言):
#include <stdio.h>
// 辅助函数:对调一个两位数的十位和个位
int swap_digits(int num) {
if (num < 10 || num > 99) {
return -1; // 不是两位数,返回错误
}
int tens = num / 10;
int ones = num % 10;
return ones * 10 + tens;
}
int main() {
int start, end;
scanf("%d %d", &start, &end);
for (int Y = start; Y <= end; Y++) {
// 题目推导出的必要条件:Y必须是11的倍数
if (Y % 11 != 0) {
continue;
}
// X的可能范围:Y - X' 是两位数,X' 在 [10, 99] 之间
// X = Y - X' 也在 [Y-99, Y-10] 之间
// 同时X本身也必须是两位数 [10, 99]
int X_lower = (Y - 99 > 10) ? (Y - 99) : 10;
int X_upper = (Y - 10 < 99) ? (Y - 10) : 99;
int found = 0; // 标记是否找到对应的X
for (int X = X_lower; X <= X_upper; X++) {
int X_swapped = swap_digits(X);
if (X_swapped != -1 && Y - X == X_swapped) {
printf("%d\n", Y);
found = 1;
break; // 找到一个X即可,无需继续检查
}
}
}
return 0;
}
第二题:李白打酒
描述:** 李白街上走,提壶去打酒。 遇店加一倍,见花喝一斗。 遇店花多少,喝光酒没有。
意思是在路上,他遇到一次酒店,壶里的酒量就会变成原来的两倍;遇到一次花,就要喝掉一斗酒,他一共遇到店 N 次,花 M 次,最后一次遇到的是花,喝光了酒,问:他一开始有多少酒?
输入格式:
输入为一行,包含两个整数 N 和 M,分别表示遇到的店和花的次数。
输出格式: 输出李白一开始有多少酒,结果保留两位小数。
输入样例:
5 10
输出样例:
81
解析与思路:
- 逆向思维:这类问题从后往前推(倒推法)通常比从前往后推(正推法)要简单。
- 确定终点:题目的终点是“最后一次遇到的是花,喝光了酒”,我们可以把这个状态作为倒推的起点。
- 定义状态:设
f(i, j)为在第i次遇店、第j次遇花时,壶里应该有多少酒。 - 倒推过程:
- 初始状态 (终点):在第
N次遇店和第M次遇花时,李白遇到了花,并且喝光了酒。f(N, M) = 1斗,因为他喝掉了1斗后变为0,所以喝之前必须有1斗。 - 递推关系:
- 如果当前状态是
f(i, j),并且这个状态是由“遇花”得到的,那么上一个状态一定是f(i, j-1),在f(i, j-1)的基础上,他遇到了花,喝掉了1斗,才变成了f(i, j)。f(i, j-1) - 1 = f(i, j),即f(i, j-1) = f(i, j) + 1。 - 如果当前状态是
f(i, j),并且这个状态是由“遇店”得到的,那么上一个状态一定是f(i-1, j),在f(i-1, j)的基础上,他遇到了店,酒量翻倍,才变成了f(i, j)。2 * f(i-1, j) = f(i, j),即f(i-1, j) = f(i, j) / 2。
- 如果当前状态是
- 初始状态 (终点):在第
- 算法实现:我们可以使用动态规划(DP)或简单的循环来实现倒推,我们需要从
f(N, M)开始,根据N和M的大小关系,交替使用“遇店”和“遇花”的逆操作,直到推算出f(0, 0),也就是初始酒量。- 初始化
wine = 1.0。 - 从最后一次操作开始向前遍历,总共的操作次数是
N + M次,最后一次是花,倒数第二次是店,依此类推。 - 我们可以循环
N + M次,在循环中,如果当前是花(即j > 0),则执行wine = wine + 1;如果当前是店(即i > 0),则执行wine = wine / 2。 - 关键在于如何判断当前步骤是“店”还是“花”,我们可以从后往前模拟这个过程,我们总共有
M次花和N次店,我们用一个变量remaining_flowers来记录还剩多少次花,remaining_shops来记录还剩多少次店。 - 初始化
remaining_flowers = M,remaining_shops = N,wine = 1.0。 - 循环
N + M次:remaining_flowers > 0,说明上一步(从当前角度看是下一步)可能是花,如果remaining_shops == 0,则上一步一定是花。- 更严谨的逻辑是:如果当前剩余的店次数
remaining_shops大于0,wine是一个偶数(这保证了倒推除法是精确的),那么上一步更可能是店,但这不是必须的,因为酒量可以是小数。 - 最优策略:总是优先选择“遇花”的逆操作,因为“遇花”的逆操作是加法,而“遇店”的逆操作是除法,为了保持精度,我们应尽量后做除法。
- 在倒推的每一步,如果还有花剩余 (
remaining_flowers > 0),我们就执行“遇花”的逆操作:wine = wine + 1,remaining_flowers--。 - 否则(即没有花剩余了),我们就执行“遇店”的逆操作:
wine = wine / 2.0,remaining_shops--。
- 循环结束后,
wine的值就是初始酒量。
- 初始化
参考代码 (C语言):
#include <stdio.h>
int main() {
int N, M; // N: 遇店次数, M: 遇花次数
scanf("%d %d", &N, &M);
double wine = 1.0; // 初始状态:最后一次遇花后,酒量为0,所以遇花前为1
int remaining_shops = N;
int remaining_flowers = M;
// 从后往前倒推,总共需要倒推 N+M 步
for (int i = 0; i < N + M; i++) {
// 优先进行“遇花”的逆操作(加法),可以避免精度损失
if (remaining_flowers > 0) {
wine += 1.0;
remaining_flowers--;
} else {
// 如果没有花剩余了,则进行“遇店”的逆操作(除法)
wine /= 2.0;
remaining_shops--;
}
}
printf("%.2f\n", wine);
return 0;
}
第三题:带分数
描述:**
100 可以表示为带分数的形式:100 = 3 + 69258 / 714。
还可以表示为:100 = 82 + 3546 / 197。
注意特征:数字 1, 9, 7, 4, 6, 3, 8, 2, 5 恰好用了一次,不重不漏。
类似这样的带分数,100 有 11 种表示法。
给定一个正整数 N,要求你找出所有形如 N = A + B / C 的带分数表示法。
要求 A, B, C 都是正整数,且 1 <= A < N,B 和 C 的数字部分包含且仅包含 1 到 9 的所有数字,且 B / C 必须是整数。
输入格式:
一个正整数 N (3 <= N <= 100)。
输出格式:
输出表示法的个数,如果没有,则输出 0。
输入样例:
100
输出样例:
11
解析与思路:
- 分析条件:
N = A + B / C,且B / C是整数,这意味着N - A必须是一个整数,B必须是C的整数倍。A的范围是[1, N-1]。B和C必须由1到9的数字组成,且每个数字只用一次,这意味着B和C合起来用掉了1-9这九个数字。A本身也是一个正整数,它的数字不能与B或C的数字重复。
- 生成数字组合:这是一个排列组合问题,核心在于如何生成
1-9的所有不重复的排列。 - 策略:
- 生成全排列:生成
1, 2, 3, 4, 5, 6, 7, 8, 9这九个数字的所有可能的全排列,共有9! = 362880种。 - 分割排列:对于每一个全排列,我们需要将其分割成三部分:
A的数字部分,B的数字部分,和C的数字部分。A是一个数,它的位数不确定,我们可以尝试在排列的开头取1到len-2位作为A的数字。- 对于排列
p = [d1, d2, d3, d4, d5, d6, d7, d8, d9]:- 尝试
A为1位数:A_str = "d1", 剩下的d2...d9需要分割成B和C。 - 尝试
A为2位数:A_str = "d1d2", 剩下的d3...d9需要分割成B和C。 - 尝试
A为k位数:A_str = "d1...dk", 剩下的d{k+1}...d9需要分割成B和C。
- 尝试
- 分割B和C:对于剩下的
m = 9 - k位数字,我们需要找到一个分割点i(1 <= i < m),使得前i位组成B,后m-i位组成C。- 剩下
d3...d9(7位),可以尝试B为1位,C为6位;B为2位,C为5位;...;B为6位,C为1位。
- 剩下
- 验证条件:对于每一种分割方式,我们得到
A,B,C三个数,然后验证:A必须小于N。B必须能被C整除 (B % C == 0)。A + B / C是否等于N。
- 生成全排列:生成
- 算法优化:
- 直接生成
9!个排列,然后对每个排列进行多重循环分割,时间复杂度是9! * (9 * 9),这在现代计算机上是完全可以接受的。 - 我们可以使用
next_permutation函数(C++)或自己实现一个全生成器来遍历所有排列。 - 在C语言中,我们可以使用
stdlib.h中的qsort和一个自定义的next_permutation函数,或者使用更简单的DFS(深度优先搜索)来生成所有排列。
- 直接生成
参考代码 (C语言):
#include <stdio.h>
#include <string.h>
#include <stdbool.h>
// 全局变量,用于计数
int count = 0;
// 存储数字1-9的排列
int digits[9];
// 检查一个数字是否包含重复数字(对于本题,由于是排列,所以天然不重复,此函数备用)
bool has_unique_digits(int num) {
bool used[10] = {false};
if (num == 0) return true;
while (num > 0) {
int d = num % 10;
if (used[d]) return false;
used[d] = true;
num /= 10;
}
return true;
}
// 生成下一个排列,返回true表示成功,false表示已经是最后一个排列
bool next_permutation(int arr[], int n) {
int i = n - 2;
while (i >= 0 && arr[i] >= arr[i + 1]) {
i--;
}
if (i < 0) {
return false; // 已经是最后一个排列
}
int j = n - 1;
while (arr[j] <= arr[i]) {
j--;
}
// 交换 arr[i] 和 arr[j]
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
// 反转 arr[i+1..n-1]
int left = i + 1;
int right = n - 1;
while (left < right) {
temp = arr[left];
arr[left] = arr[right];
arr[right] = temp;
left++;
right--;
}
return true;
}
int main() {
int N;
scanf("%d", &N);
// 初始化digits为1-9
for (int i = 0; i < 9; i++) {
digits[i] = i + 1;
}
do {
// 遍历所有可能的A的位数
for (int len_a = 1; len_a < 9; len_a++) {
// 构造A
int A = 0;
for (int i = 0; i < len_a; i++) {
A = A * 10 + digits[i];
}
if (A >= N) continue; // A必须小于N
// 剩余的数字用于构造B和C
int remaining_len = 9 - len_a;
if (remaining_len < 2) continue; // B和C至少各需要1位数字
// 遍历所有可能的B的位数
for (int len_b = 1; len_b < remaining_len; len_b++) {
int len_c = remaining_len - len_b;
// 构造B
int B = 0;
for (int i = 0; i < len_b; i++) {
B = B * 10 + digits[len_a + i];
}
// 构造C
int C = 0;
for (int i = 0; i < len_c; i++) {
C = C * 10 + digits[len_a + len_b + i];
}
// 验证条件
if (C == 0) continue; // 避免除以0
if (B % C == 0) {
if (A + B / C == N) {
count++;
}
}
}
}
} while (next_permutation(digits, 9));
printf("%d\n", count);
return 0;
}
备赛建议
- 基础扎实:熟练掌握C语言的指针、数组、字符串处理、结构体、文件操作等基础知识。
- 算法核心:重点掌握排序、查找、递归与分治、贪心、动态规划、深度优先搜索、广度优先搜索等基本算法思想。
- 数学能力:蓝桥杯常考数论(素数、约数、同余)、组合数学(排列、组合)和简单的几何计算,多刷这类题目。
- 代码能力:提高代码的编写速度和准确性,比赛时间宝贵,平时就要注意限时训练。
- 模拟实战:找历年真题进行模拟,熟悉题型、难度和时间分配,像上面这样的真题,一定要亲手敲一遍并理解透彻。
希望这些资料和解析对您的备赛有所帮助!祝您在蓝桥杯中取得好成绩!


