Tokenizer 是编译器、解释器或任何需要解析文本结构(如代码、配置文件、数据格式)的核心组件,它的主要任务是将一长串字符(源代码)分解成一系列有意义的“标记”(Tokens)。
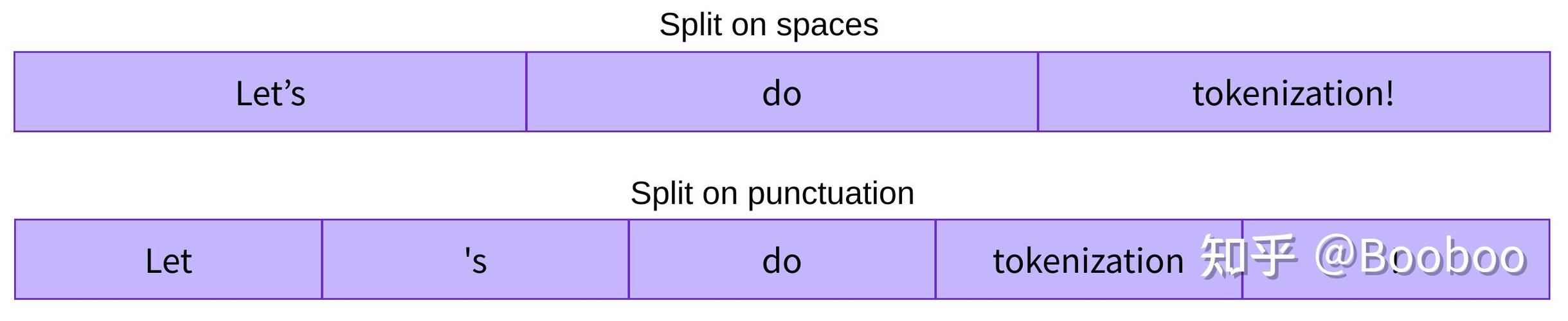
什么是 Tokenizer?它的目标是什么?
想象一下你要读一句话:"The quick brown fox jumps over the lazy dog."。
你的大脑会自动将这个句子分解成单词:"The", "quick", "brown", "fox", "jumps", "over", "the", "lazy", "dog",你可能还会识别出标点符号 。
Tokenizer 就像你大脑的这个功能,但它处理的是计算机语言(如 C、Python)或自定义格式的文本。
Tokenizer 的目标:
- 扫描: 逐个字符地读取输入源代码。
- 分类: 将连续的字符序列分组,并根据其含义分类成一个 Token。
- 输出: 产生一个 Token 序列,通常是一个列表或流。
Token 是什么? 一个 Token 通常包含至少两个部分:

- 类型: 这个标记代表什么?是一个关键字(
IF,WHILE)、一个标识符(变量名)、一个数字(123)、一个操作符(, )还是一个符号(, )。 - 值: 标记对应的原始字符串,类型为
IDENTIFIER,值为myVariable。
对于 C 语言代码片段:
int x = 10;
Tokenizer 会输出以下 Token 序列:
| Token 类型 | Token 值 |
|---|---|
KEYWORD |
int |
IDENTIFIER |
x |
OPERATOR |
|
NUMBER |
10 |
SYMBOL |
Tokenizer 的基本工作原理
实现一个 Tokenizer 通常遵循以下步骤:
-
初始化:
 (图片来源网络,侵删)
(图片来源网络,侵删)- 读取输入源代码到一个字符串或逐个字符读取。
- 初始化一个位置指针(如
current_index),指向当前正在处理的字符。 - 创建一个空列表来存放生成的 Token。
-
循环处理:
当位置指针没有到达输入末尾时,循环执行以下操作。
-
跳过空白字符:
- 移动指针,跳过所有无意义的空白字符,如空格 (
`)、制表符 (\t)、换行符 (\n)、回车符 (\r`) 等,这些字符通常不参与 Token 的构成,但用于分隔 Token。
- 移动指针,跳过所有无意义的空白字符,如空格 (
-
识别 Token:
- 查看当前指针指向的字符。
- 根据第一个字符来判断 Token 的可能类型,然后继续读取后续字符,直到整个 Token 被识别出来。
- 识别逻辑示例:
- 如果是字母或下划线
_,则一直读取,直到遇到非字母、数字或下划线的字符,这构成一个标识符或关键字。 - 如果是数字
0-9,则一直读取,直到遇到非数字的字符,这构成一个数字。 - 如果是 , , , 等,则通常一个字符就是一个操作符。
- 如果是 , ,
<,>,则需要看下一个字符是否构成 , ,<=,>=等复合操作符。 - 如果是 , , , , , 等,则单个字符就是一个符号。
- 如果是字母或下划线
-
创建并存储 Token:
- 根据识别出的字符串和类型,创建一个 Token 结构体。
- 将这个 Token 添加到 Token 列表中。
-
更新指针并循环:
- 将位置指针更新到刚刚识别完的 Token 的下一个位置。
- 回到第 2 步,继续处理。
C 语言实现示例
下面是一个完整的、可运行的 C 语言 Tokenizer 实现,它可以处理简单的 C 语言代码片段。
1 定义 Token 结构体
我们需要定义 Token 的结构,使用 enum 来定义 Token 类型是一个非常好的实践。
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <ctype.h> // 用于字符处理函数,如 isalpha, isdigit
// 定义 Token 类型
typedef enum {
// 特殊 Token
TOKEN_EOF, // 文件结束
TOKEN_ERROR, // 错误 Token
// 关键字
TOKEN_INT,
TOKEN_RETURN,
// 标识符和字面量
TOKEN_IDENTIFIER,
TOKEN_NUMBER,
// 操作符
TOKEN_PLUS,
TOKEN_MINUS,
TOKEN_ASTERISK,
TOKEN_SLASH,
TOKEN_ASSIGN, // =
// 符号
TOKEN_SEMICOLON, // ;
TOKEN_LPAREN, // (
TOKEN_RPAREN, // )
TOKEN_LBRACE, // {
TOKEN_RBRACE, // }
} TokenType;
// 定义 Token 结构体
typedef struct {
TokenType type;
char lexeme[100]; // 存储原始字符串
} Token;
2 Tokenizer 核心逻辑
这是实现 Tokenizer 的核心函数。
// 函数声明
Token get_next_token(const char** source);
// 从源代码中获取下一个 Token
Token get_next_token(const char** source) {
Token token;
const char* s = *source;
int len = 0;
// 跳过空白字符
while (isspace(*s)) {
s++;
}
// 检查是否到达文件末尾
if (*s == '\0') {
token.type = TOKEN_EOF;
token.lexeme[0] = '\0';
*source = s;
return token;
}
// 1. 处理标识符和关键字
if (isalpha(*s) || *s == '_') {
len = 0;
while (isalnum(s[len]) || s[len] == '_') {
token.lexeme[len] = s[len];
len++;
}
token.lexeme[len] = '\0';
// 检查是否是关键字
if (strcmp(token.lexeme, "int") == 0) {
token.type = TOKEN_INT;
} else if (strcmp(token.lexeme, "return") == 0) {
token.type = TOKEN_RETURN;
} else {
token.type = TOKEN_IDENTIFIER;
}
*source = s + len;
return token;
}
// 2. 处理数字
if (isdigit(*s)) {
len = 0;
while (isdigit(s[len])) {
token.lexeme[len] = s[len];
len++;
}
token.lexeme[len] = '\0';
token.type = TOKEN_NUMBER;
*source = s + len;
return token;
}
// 3. 处理操作符和符号
switch (*s) {
case '+': token.type = TOKEN_PLUS; break;
case '-': token.type = TOKEN_MINUS; break;
case '*': token.type = TOKEN_ASTERISK; break;
case '/': token.type = TOKEN_SLASH; break;
case '=': token.type = TOKEN_ASSIGN; break;
case ';': token.type = TOKEN_SEMICOLON; break;
case '(': token.type = TOKEN_LPAREN; break;
case ')': token.type = TOKEN_RPAREN; break;
case '{': token.type = TOKEN_LBRACE; break;
case '}': token.type = TOKEN_RBRACE; break;
default:
// 未知字符,视为错误
token.type = TOKEN_ERROR;
token.lexeme[0] = *s;
token.lexeme[1] = '\0';
*source = s + 1;
return token;
}
token.lexeme[0] = *s;
token.lexeme[1] = '\0';
*source = s + 1;
return token;
}
3 辅助函数和主函数
为了方便查看结果,我们添加一个打印 Token 的函数和一个主函数来驱动整个流程。
// 将 Token 类型转换为可读的字符串
const char* token_type_to_string(TokenType type) {
switch (type) {
case TOKEN_EOF: return "EOF";
case TOKEN_ERROR: return "ERROR";
case TOKEN_INT: return "INT";
case TOKEN_RETURN: return "RETURN";
case TOKEN_IDENTIFIER: return "IDENTIFIER";
case TOKEN_NUMBER: return "NUMBER";
case TOKEN_PLUS: return "PLUS";
case TOKEN_MINUS: return "MINUS";
case TOKEN_ASTERISK: return "ASTERISK";
case TOKEN_SLASH: return "SLASH";
case TOKEN_ASSIGN: return "ASSIGN";
case TOKEN_SEMICOLON: return "SEMICOLON";
case TOKEN_LPAREN: return "LPAREN";
case TOKEN_RPAREN: return "RPAREN";
case TOKEN_LBRACE: return "LBRACE";
case TOKEN_RBRACE: return "RBRACE";
default: return "UNKNOWN";
}
}
// 打印 Token
void print_token(Token token) {
printf("Token: %-12s Lexeme: '%s'\n",
token_type_to_string(token.type),
token.lexeme);
}
int main() {
// 示例 C 代码
const char* source_code =
"int main() {\n"
" int x = 10 + 5;\n"
" return x;\n"
"}\n";
printf("Source Code:\n%s\n", source_code);
printf("\n--- Tokenizing ---\n");
const char* current = source_code;
Token token;
do {
token = get_next_token(¤t);
print_token(token);
} while (token.type != TOKEN_EOF && token.type != TOKEN_ERROR);
if (token.type == TOKEN_ERROR) {
printf("\nLexical error encountered!\n");
}
return 0;
}
4 如何编译和运行
- 将以上所有代码保存为一个文件,
tokenizer.c。 - 使用 gcc 进行编译:
gcc tokenizer.c -o tokenizer
- 运行生成的可执行文件:
./tokenizer
5 预期输出
你将看到如下输出:
Source Code:
int main() {
int x = 10 + 5;
return x;
}
--- Tokenizing ---
Token: INT Lexeme: 'int'
Token: IDENTIFIER Lexeme: 'main'
Token: LPAREN Lexeme: '('
Token: RPAREN Lexeme: ')'
Token: LBRACE Lexeme: '{'
Token: INT Lexeme: 'int'
Token: IDENTIFIER Lexeme: 'x'
Token: ASSIGN Lexeme: '='
Token: NUMBER Lexeme: '10'
Token: PLUS Lexeme: '+'
Token: NUMBER Lexeme: '5'
Token: SEMICOLON Lexeme: ';'
Token: RETURN Lexeme: 'return'
Token: IDENTIFIER Lexeme: 'x'
Token: SEMICOLON Lexeme: ';'
Token: RBRACE Lexeme: '}'
Token: EOF Lexeme: ''进阶与改进
这个简单的示例展示了 Tokenizer 的基本原理,一个更完善的 Tokenizer 还需要考虑:
- 多字符操作符: 像 , ,
<=,>=, , 等,你需要在switch语句中增加对s[1]的判断。 - 注释: 需要识别 单行注释和 多行注释,并跳过它们。
- 字符串字面量: 需要识别 内的内容,并处理转义字符(如
\n,\",\\)。 - 浮点数: 需要识别
14,.5,1e10这样的浮点数。 - 错误处理: 更详细的错误报告,例如指出错误发生的行号和列号。
- 更高效的设计: 对于非常大的文件,一次性读入所有内存可能不高效,可以改为逐行读取或按块读取,指针传递 (
const char**) 的方式已经非常高效。 - 使用 Flex/Lex: 在实际开发中,没有人会手动写一个复杂的 Tokenizer,通常会使用像 Flex (在 Linux/Unix 上) 或 Lex (在 Windows 上) 这样的工具,你只需要用特定的语法规则描述你的 Token,Flex 就能自动生成一个高效的 C 语言 Tokenizer 代码。
这个 C 语言实现的 Tokenizer 是一个非常棒的起点,它涵盖了编译器前端最基础也最核心的概念之一。


