float 和 double 都是用来表示带小数的数字(浮点数)的,它们最核心的区别在于精度和存储空间的大小:

float(单精度浮点数):占用 4 字节 (32位) 内存,提供约 6-9 位有效数字的精度。double(双精度浮点数):占用 8 字节 (64位) 内存,提供约 15-17 位有效数字的精度。
在绝大多数情况下,优先使用 double,因为它的精度更高,性能在现代CPU上与float相差无几,能避免很多潜在的精度错误,只有在内存空间极其受限(如嵌入式系统)或需要处理大量数据且对精度要求不高时,才考虑使用 float。
详细的对比表格
| 特性 | float (单精度) |
double (双精度) |
|---|---|---|
| 关键字 | float |
double |
| 占用内存 | 4 字节 (32 bits) | 8 字节 (64 bits) |
| 有效数字 | 约 6-9 位十进制数 | 约 15-17 位十进制数 |
| 指数范围 | 较小 (约 ±38) | 较大 (约 ±308) |
| 默认类型 | 在表达式中,float 会自动提升为 double |
C 语言中所有浮点字面量(如 14)的默认类型 |
| 后缀 | 可以使用 f 或 F 作为后缀 (如 14f) |
可以使用 l 或 L 作为后缀 (如 3.14L),但通常省略 |
| 性能 | 在老旧或特定架构的CPU上可能稍快 | 在现代通用CPU上,性能与float基本相同,甚至有时更快 |
| 使用场景 | 图形学(GPU大量使用)、嵌入式系统、内存敏感型应用 | 科学计算、金融、绝大多数通用编程 |
代码示例:直观感受精度差异
下面的代码可以清晰地展示 float 和 double 在精度上的巨大差别。
#include <stdio.h>
int main() {
// 定义一个 float 和一个 double 变量
float f_num = 123.456789f;
double d_num = 123.456789;
printf("这是一个 float 变量: %f\n", f_num);
printf("这是一个 double 变量: %lf\n", d_num);
// 使用 %.15 来打印更多位小数,观察精度损失
printf("\n打印更多位小数观察精度:\n");
printf("float: %.15f\n", f_num); // 注意这里,float会被提升为double再打印
printf("double: %.15lf\n", d_num);
// 更极端的例子
float f_big = 123456789.123456789f;
double d_big = 123456789.123456789;
printf("\n处理更大的数:\n");
printf("float: %.9f\n", f_big); // 只能精确表示前几位
printf("double: %.9f\n", d_big); // 能精确表示更多位
return 0;
}
可能的输出:
这是一个 float 变量: 123.456787
这是一个 double 变量: 123.456789
打印更多位小数观察精度:
float: 123.456787109375000
double: 123.456789000000000
处理更大的数:
float: 123456792.000000000
double: 123456789.123456789分析:

- 从第一个输出就能看出,
float在存储456789时就已经丢失了精度,变成了456787,而double则准确地保存了它。 - 第二个输出显示,
float的有效数字大约在7-8位,而double可以轻松达到15位以上。 - 第三个例子中,
float的精度损失非常严重,已经无法正确表示原始数值。
为什么会有精度问题?(IEEE 754 标准)
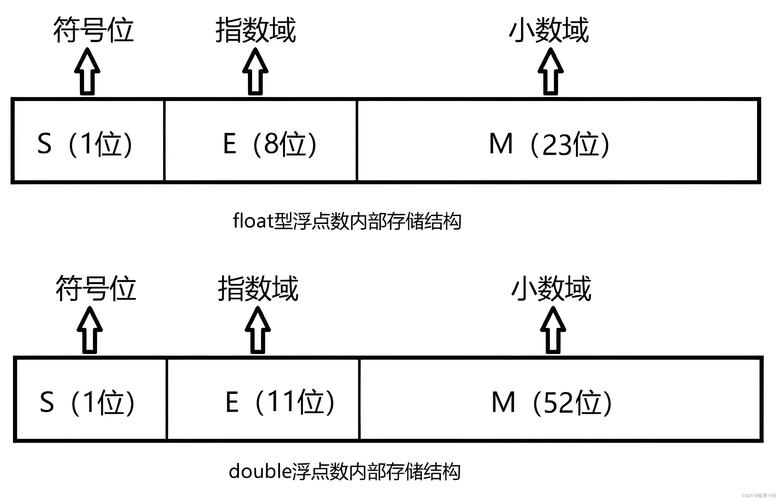
float 和 double 的精度问题源于它们在计算机中的存储方式,遵循 IEEE 754 浮点数标准,一个浮点数由三部分组成:
- 符号位:1位,表示正负。
- 指数位:用于表示数值的大小范围(数量级)。
float有 8 位指数。double有 11 位指数。
- 尾数位:用于表示数值的精度(有效数字)。
float有 23 位尾数。double有 52 位尾数。
关键点: 计算机使用二进制来存储这些数,很多我们熟悉的十进制小数(如 1)在二进制中是无限循环小数。
经典例子:1 的二进制表示
十进制的 1 转换成二进制是 000110011001100...(无限循环),由于计算机的尾数位数有限,它只能存储一个近似值。
代码验证:
#include <stdio.h>
int main() {
float f = 0.1f;
double d = 0.1;
printf("float 0.1 的实际值: %.20f\n", f);
printf("double 0.1 的实际值: %.20lf\n", d);
// 看看 0.1 + 0.2 的情况
float f_result = 0.1f + 0.2f;
double d_result = 0.1 + 0.2;
printf("\nfloat 0.1 + 0.2 = %.20f\n", f_result);
printf("double 0.1 + 0.2 = %.20lf\n", d_result);
// 使用一个接近的数来判断
printf("\nfloat 结果 == 0.3? %s\n", (f_result == 0.3f) ? "Yes" : "No");
printf("double 结果 == 0.3? %s\n", (d_result == 0.3) ? "Yes" : "No");
return 0;
}
输出:
float 0.1 的实际值: 0.10000000149011611938
double 0.1 的实际值: 0.10000000000000000555
float 0.1 + 0.2 = 0.30000001192092895508
double 0.1 + 0.2 = 0.30000000000000004441
float 结果 == 0.3? No
double 结果 == 0.3? No注意: 即使是精度更高的 double,1 + 0.2 的结果也不严格等于 3,只是非常接近,这就是为什么在金融等需要绝对精度的领域,不能直接使用 float 或 double,而应该使用专门的库(如 GMP)或定点数表示法。
常见问题与最佳实践
Q1: 为什么 float 的字面量需要 f 后缀?
C 语言规定,不带任何后缀的小数(如 14)的默认类型是 double,如果你想把一个数明确地赋值给 float 变量,有两种方法:
- 使用
f或F后缀:float pi = 3.14f; - 进行强制类型转换:
float pi = (float)3.14;
如果不加 f,编译器会先把 14 当作 double 处理,然后再将这个 double 值隐式转换为 float 赋给变量,虽然这通常没问题,但显式使用 f 更清晰,能避免不必要的精度转换。
Q2: 什么时候应该用 float?
- 内存限制:当你需要存储数百万个浮点数时,使用
float可以节省一半的内存。 - GPU 编程:图形处理单元对
float的计算进行了高度优化,在图形学、游戏开发中广泛使用。 - 嵌入式系统:在资源非常有限的微控制器上,
float可能是唯一可行的浮点类型。
Q3: 如何避免浮点数比较的陷阱?
永远不要用 来直接比较两个浮点数是否相等! 由于精度问题,它们可能非常接近但不完全相等。
正确做法: 定义一个很小的“误差范围”(epsilon),判断两个数的差值是否在这个范围内。
#include <stdio.h>
#include <math.h> // 需要 math.h 来使用 fabs()
// 判断两个浮点数是否“相等”
int is_float_equal(float a, float b, float epsilon) {
return fabs(a - b) < epsilon;
}
int main() {
float a = 0.1f + 0.2f;
float b = 0.3f;
// 错误的方式
if (a == b) {
printf("a 严格等于 b\n"); // 这行代码不会执行
} else {
printf("a 不严格等于 b\n"); // 这行代码会执行
}
// 正确的方式
float epsilon = 0.00001f;
if (is_float_equal(a, b, epsilon)) {
printf("a 和 b 在误差范围内相等\n"); // 这行代码会执行
} else {
printf("a 和 b 在误差范围内不相等\n");
}
return 0;
}
| 特性 | float |
double |
|---|---|---|
| 大小 | 4 字节 | 8 字节 |
| 精度 | 低 (6-9位) | 高 (15-17位) |
| 默认类型 | 非默认 | 默认 |
| 推荐度 | 特殊场景使用 | 优先使用 |
记住这个简单的原则:除非你有充分的理由(如内存限制),否则请始终使用 double,它能给你带来更高的精度,并且在现代计算机上几乎没有任何性能损失,是更安全、更稳健的选择。


