链表是一种基础且非常重要的数据结构,与数组不同,链表中的元素在内存中不是连续存储的,它由一系列节点组成,每个节点包含两部分:
(图片来源网络,侵删)
- 数据:节点存储的实际值。
- 指针:指向下一个节点的内存地址。
通过这种方式,链表可以动态地增加或减少长度,而不需要像数组一样预先分配固定大小的内存。
链表的基本概念
节点
链表的基本单元是节点,在 C 语言中,我们通常使用 struct 来定义节点结构。
// 定义一个链表节点
typedef struct Node {
int data; // 数据部分,这里以整数为例
struct Node* next; // 指针部分,指向下一个节点
} Node;
typedef关键字为我们创建了一个新的类型别名Node,使得代码更易读。
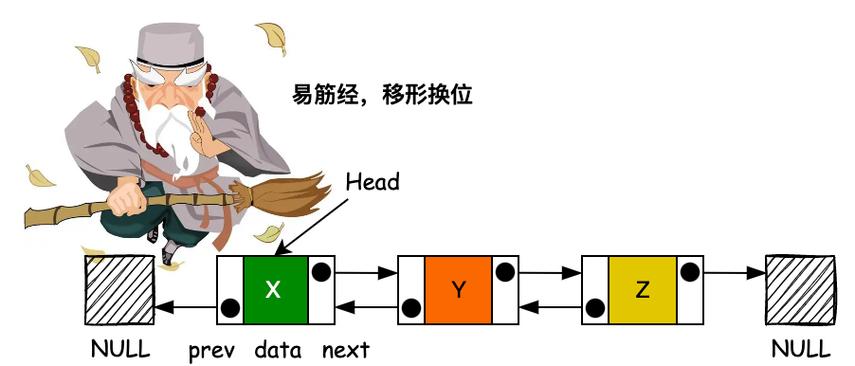
头指针
链表的第一个节点被称为头节点,我们通常用一个指针(称为头指针)来指向头节点,如果链表为空,头指针就指向 NULL。

(图片来源网络,侵删)
链表的类型
- 单向链表:最简单的链表,每个节点只包含一个指向下一个节点的指针。
- 双向链表:每个节点包含两个指针,一个指向前一个节点,一个指向后一个节点,这使得双向遍历成为可能。
- 循环链表:链表的最后一个节点的
next指针不指向NULL,而是指向头节点,形成一个环。
在本教程中,我们主要讲解最基础的单向链表。
单向链表的完整实现示例
下面是一个完整的 C 程序,展示了如何创建、遍历、插入和删除单向链表中的节点。
#include <stdio.h>
#include <stdlib.h> // 用于 malloc 和 free
// 1. 定义链表节点
typedef struct Node {
int data;
struct Node* next;
} Node;
// 2. 函数声明
Node* createNode(int data);
void insertAtEnd(Node** head, int data);
void insertAtBeginning(Node** head, int data);
void deleteNode(Node** head, int key);
void printList(Node* head);
void freeList(Node* head);
// 3. 主函数 - 驱动程序
int main() {
Node* head = NULL; // 初始化一个空链表,头指针为 NULL
// 在链表末尾插入元素
insertAtEnd(&head, 10);
insertAtEnd(&head, 20);
insertAtEnd(&head, 30);
printf("在末尾插入 10, 20, 30 后的链表: ");
printList(head); // 输出: 10 -> 20 -> 30 -> NULL
// 在链表开头插入元素
insertAtBeginning(&head, 5);
printf("\n在开头插入 5 后的链表: ");
printList(head); // 输出: 5 -> 10 -> 20 -> 30 -> NULL
// 删除一个元素
deleteNode(&head, 20);
printf("\n删除 20 后的链表: ");
printList(head); // 输出: 5 -> 10 -> 30 -> NULL
// 释放整个链表的内存
freeList(head);
head = NULL; // 防止悬空指针
printf("\n释放链表后的链表: ");
printList(head); // 输出: NULL
return 0;
}
// 4. 函数实现
/**
* @brief 创建一个新节点
* @param data 要存储的数据
* @return 指向新节点的指针
*/
Node* createNode(int data) {
Node* newNode = (Node*)malloc(sizeof(Node));
if (newNode == NULL) {
printf("内存分配失败!\n");
exit(1);
}
newNode->data = data;
newNode->next = NULL;
return newNode;
}
/**
* @brief 在链表末尾插入一个新节点
* @param head 指向头指针的指针 (非常重要!)
* @param data 要插入的数据
*/
void insertAtEnd(Node** head, int data) {
Node* newNode = createNode(data);
// 如果链表为空,新节点就是头节点
if (*head == NULL) {
*head = newNode;
return;
}
// 否则,遍历到链表的最后一个节点
Node* last = *head;
while (last->next != NULL) {
last = last->next;
}
// 将最后一个节点的 next 指向新节点
last->next = newNode;
}
/**
* @brief 在链表开头插入一个新节点
* @param head 指向头指针的指针
* @param data 要插入的数据
*/
void insertAtBeginning(Node** head, int data) {
Node* newNode = createNode(data);
newNode->next = *head; // 新节点的 next 指向原来的头节点
*head = newNode; // 头指针现在指向新节点
}
/**
* @brief 删除链表中第一个匹配 key 的节点
* @param head 指向头指针的指针
* @param key 要删除的值
*/
void deleteNode(Node** head, int key) {
Node* temp = *head;
Node* prev = NULL;
// 如果头节点本身就是要找的节点
if (temp != NULL && temp->data == key) {
*head = temp->next; // 头指针指向下一个节点
free(temp); // 释放旧头节点的内存
return;
}
// 遍历链表,寻找要删除的节点
while (temp != NULL && temp->data != key) {
prev = temp;
temp = temp->next;
}
// 如果没找到 key
if (temp == NULL) {
printf("未找到值为 %d 的节点,\n", key);
return;
}
// 找到了,prev->next 指向 temp 的下一个节点,跳过 temp
prev->next = temp->next;
free(temp); // 释放被删除节点的内存
}
/**
* @brief 打印链表
* @param head 头指针
*/
void printList(Node* head) {
Node* current = head;
while (current != NULL) {
printf("%d -> ", current->data);
current = current->next;
}
printf("NULL\n");
}
/**
* @brief 释放整个链表的内存
* @param head 头指针
*/
void freeList(Node* head) {
Node* current = head;
Node* next;
while (current != NULL) {
next = current->next; // 先保存下一个节点的地址
free(current); // 释放当前节点
current = next; // 移动到下一个节点
}
}
核心要点解析
为什么 insertAtEnd 和 deleteNode 的参数是 Node** head(指向指针的指针)?
这是 C 语言中处理链表的一个经典且重要的技巧。
-
Node* head(指针)*如果函数只接收一个 `Node`,它得到的是头指针的一个副本**,在函数内部修改这个副本(让它指向一个新的节点)并不会影响外部的原始头指针,这会导致插入操作无法真正改变链表的结构。 (图片来源网络,侵删)
(图片来源网络,侵删) -
`Node head
(指向指针的指针)**:当我们将&head(头指针的地址)传递给函数时,函数内部通过*head` 可以直接访问和修改外部的原始头指针。
例子:在空链表开头插入
- 外部
head是NULL。 - 我们调用
insertAtBeginning(&head, 5)。 - 函数内部,
head参数接收的是外部head的地址。 newNode->next = *head;变成了newNode->next = NULL;。*head = newNode;这句代码将外部的head变量的值修改为newNode的地址。- 函数返回后,外部的
head现在正确地指向了新创建的节点。
对于 insertAtEnd,当链表为空时,也需要修改头指针,所以也需要 Node**,对于非空情况,虽然可以直接使用 *head,但为了接口的一致性,通常也使用 Node**。
链表 vs. 数组
| 特性 | 链表 | 数组 |
|---|---|---|
| 内存分配 | 动态,非连续 | 静态或动态,连续 |
| 大小 | 动态可变 | 固定(静态)或可变(动态,但成本高) |
| 插入/删除 | 高效 (O(1) 头部, O(n) 中间/尾部) | 低效 (O(n),需要移动大量元素) |
| 访问元素 | 低效 (O(n),必须从头遍历) | 高效 (O(1),通过索引直接访问) |
| 内存开销 | 每个节点需要额外的指针空间 | 无额外开销 |
| 缓存性能 | 较差(内存不连续) | 较好(内存连续,预取效果好) |
- 如果你需要频繁地插入和删除数据,并且数据量不固定,链表是更好的选择。
- 如果你需要频繁地随机访问数据(通过索引),并且数据量固定,数组是更好的选择。
扩展:双向链表
双向链表的节点定义如下:
typedef struct DNode {
int data;
struct DNode* prev; // 指向前一个节点
struct DNode* next; // 指向后一个节点
} DNode;
双向链表的优势在于可以双向遍历,并且在删除一个已知节点时效率更高(不需要像单向链表那样先找到前一个节点),但它的实现更复杂,每个节点多占用一个指针的内存空间。


