直接调用body字段会返回文章的全部内容,这通常会导致列表页非常臃肿、加载速度变慢,并且影响用户体验。
下面我将为你提供几种常用的方法,从最简单到最推荐,并解释其优缺点。
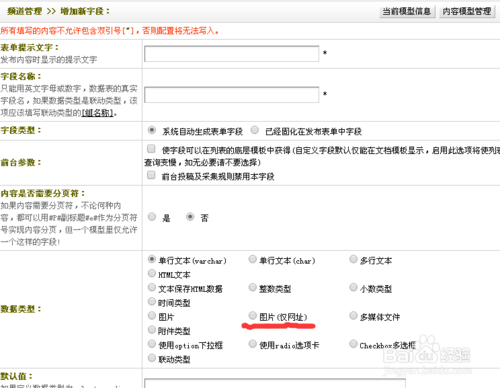
直接调用(不推荐)
这是最直接的方法,但正如前面所说,强烈不推荐在生产环境中使用,仅用于测试。
在列表页模板文件 示例代码: 缺点: 这是最标准、最推荐的方法,在发布文章时,手动填写“( 步骤: 示例代码: 代码解释: 优点: 如果因为某些原因(比如历史数据没有摘要)你必须在列表页显示 方法:
使用 示例代码: 代码解释: 改进版(先转文本再截取): 优点: 缺点: 最终建议: 希望这个详细的解释能帮助你解决问题!list_article.htm 中,使用 {dede:field.body/}
{dede:list pagesize='10'}
<h3><a href="[field:arcurl/]">[field:title/]</a></h3>
<p>发布时间:[field:pubdate function="MyDate('Y-m-d H:i',@me)"/]</p>
<!-- 直接调用body,会显示文章全部内容 -->
<div class="content">
[field:body/]
</div>
<hr />
{/dede:list}
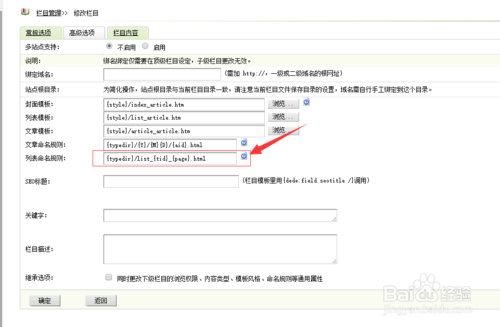
调用文章摘要(推荐方法)
description字段),或者在后台设置“自动提取摘要”。
{dede:field.description/}
{dede:list pagesize='10'}
<h3><a href="[field:arcurl/]">[field:title/]</a></h3>
<p>发布时间:[field:pubdate function="MyDate('Y-m-d H:i',@me)"/]</p>
<!-- 调用文章摘要,这是最佳实践 -->
<div class="summary">
[field:description function='cn_substr(@me, 200)'/]...
</div>
<hr />
{/dede:list}
[field:description/]:调用文章摘要。function='cn_substr(@me, 200)':这是一个自定义函数,cn_substr 是织梦自带的截取字符串函数。@me 代表当前字段的值(即摘要内容),200 是截取的字符数,这样即使后台没有填写摘要,也不会显示错误,并且可以控制摘要长度。
手动截取
body 内容(备选方法)body 的部分内容,可以手动截取 body 的前 N 个字符。cn_substr 函数来截取 body 字段。{dede:list pagesize='10'}
<h3><a href="[field:arcurl/]">[field:title/]</a></h3>
<p>发布时间:[field:pubdate function="MyDate('Y-m-d H:i',@me)"/]</p>
<!-- 手动截取body内容的前200个字符作为摘要 -->
<div class="content-summary">
[field:body function='cn_html2text(@me)'/]...
</div>
<hr />
{/dede:list}
[field:body function='cn_html2text(@me)'/]:
@me:代表 body 字段的全部内容。cn_html2text():这是一个非常实用的织梦函数,它会将HTML标签(如 <p>, <img>, <a> 等)全部去除,只保留纯文本,这样可以避免在列表页显示杂乱的HTML代码。cn_substr():在 cn_html2text 外层再套一个 cn_substr,用于控制最终显示的字符数。{dede:list pagesize='10'}
...
<div class="content-summary">
<!-- 先去除HTML标签,再截取前200个字符 -->
[field:body function='cn_substr(cn_html2text(@me), 200)'/]...
</div>
...
{/dede:list}
cn_html2text 避免了HTML格式错乱。
body 内容,只是处理方式不同。
总结与建议
方法
调用标签
优点
缺点
推荐度
直接调用
[field:body/]实现简单
性能极差、体验差、SEO差
☆☆☆☆☆ (不推荐)
调用摘要
[field:description/]性能好、体验佳、SEO优
需要手动填写摘要
★★★★★ (强烈推荐)
截取Body
[field:body function='...']灵活,可处理无摘要文章
性能一般,摘要质量不高
★★★☆☆ (备选方案)


