什么是编译?
编译 是将人类可读的源代码(如 .c 文件)转换成计算机硬件(CPU)能直接理解和执行的机器码(如可执行文件 .exe)的过程。

这个过程远不止“一键转换”那么简单,它通常由几个紧密相连的阶段组成。
C 语言编译的四个核心阶段
一个典型的 C 编译过程(以 GCC 编译器为例)主要包含以下四个阶段:
阶段 1:预处理
这是编译的第一步,由预处理器 完成,它主要负责处理以 开头的预处理器指令。
主要任务:

-
文件包含 (
#include)- 将
#include <stdio.h>或#include "myheader.h"这样的指令替换为对应文件的实际内容。 < >通常用于编译器自带的头文件(系统路径), 通常用于用户自己编写的头文件(当前目录或指定路径)。- 目的:把所有需要的声明和定义都汇集到一个文件中,方便后续编译。
- 将
-
宏展开 (
#define)- 将代码中所有的宏标识符替换为其定义的内容。
#define PI 3.14159,代码中所有出现的PI都会被替换成14159。- 对于带参数的宏,如
#define SQUARE(x) ((x) * (x)),SQUARE(a+b)会被替换成((a+b) * (a+b))。
-
条件编译 (
#if,#ifdef,#ifndef,#else,#endif)- 根据条件决定哪些代码块被包含进最终的源文件中,哪些被忽略。
- 这常用于跨平台开发和调试。
#ifdef DEBUG printf("Debugging information...\n"); #endif只有在定义了
DEBUG宏的情况下,printf这一行才会被保留。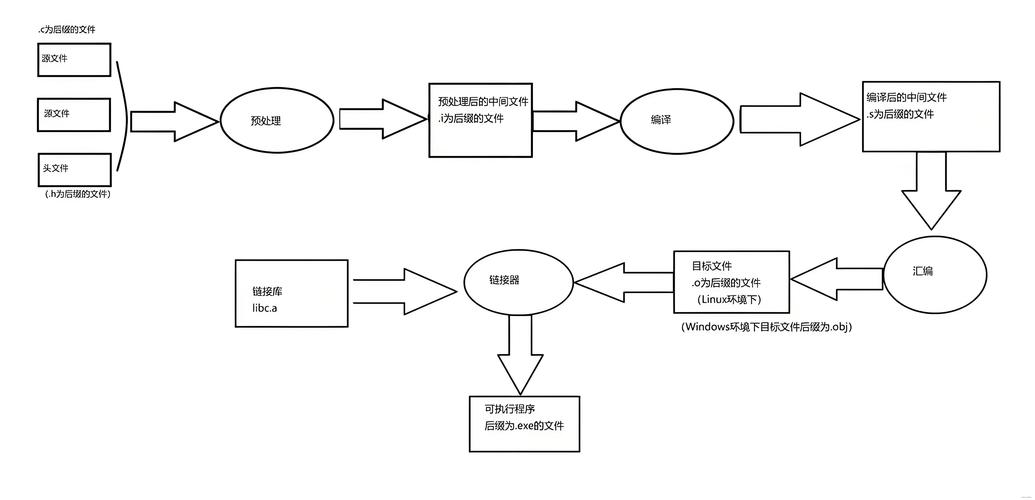 (图片来源网络,侵删)
(图片来源网络,侵删)
如何查看预处理后的结果?
使用 -E 选项,并使用 -o 将结果输出到一个文件中:
gcc -E hello.c -o hello.i
hello.i 文件就是预处理后的结果,它是一个巨大的 .c 文件,包含了所有头文件的内容和宏展开后的代码。
阶段 2:编译
这是编译器的核心工作阶段,由编译器 完成,它将预处理后的代码(.i 文件)翻译成汇编代码。
主要任务:
- 词法分析:将源代码字符流切分成一个个有意义的“单词”(称为 Token),如关键字
int、标识符main、操作符 、常量10等。 - 语法分析:根据 C 语言的语法规则,检查 Token 序列是否构成合法的语法结构(如声明、语句、函数等),并构建一个语法树。
- 语义分析:检查代码的逻辑含义是否正确,变量是否在使用前声明了?类型是否匹配?函数调用参数是否正确?
- 优化:对代码进行一些优化,以提高运行效率或减少代码体积。
- 生成汇编代码:将语法树翻译成特定 CPU 架构的汇编语言(
.s文件),汇编语言是机器码的文本表示,每条指令通常对应一条机器指令。
如何查看编译后的汇编代码?
使用 -S 选项:
gcc -S hello.i -o hello.s
hello.s 文件就是汇编代码,内容看起来像这样:
.file "hello.c"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl $.LC0, %edi
call puts
movl $0, %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.section .rodata
.LC0:
.string "Hello, World!"
.ident "GCC: (Ubuntu 9.4.0-1ubuntu1~20.04.1) 9.4.0"
.section .note.GNU-stack,"",@progbits
阶段 3:汇编
这个阶段由汇编器 完成,它将汇编代码(.s 文件)翻译成机器码,生成目标文件(.o 文件 或 .obj 文件)。
主要任务:
- 将每一条汇编指令翻译成对应的二进制机器码。
- 目标文件包含了程序的机器码、数据以及一些关于函数和变量的信息(如符号表),但它还不是一个完整的可执行程序,因为它可能还依赖其他文件中的函数或变量。
如何生成目标文件?
使用 -c 选项:
gcc -c hello.s -o hello.o
hello.o 就是目标文件,在 Linux/macOS 下,可以用 file 命令查看:
file hello.o # 输出: hello.o: ELF 64-bit LSB relocatable, x86-64, version 1 (SYSV), not stripped
这表明它是一个为 Linux x86-64 架构准备的可重定位文件。
阶段 4:链接
这是最后一步,由链接器 完成,它将一个或多个目标文件(.o 文件)以及所需的库文件(如 C 标准库 libc)组合在一起,生成一个最终的可执行文件。
主要任务:
- 合并代码段和数据段:将所有目标文件的代码和数据合并到同一个文件中。
- 符号解析:解决目标文件之间的“引用”问题。
hello.o中调用了printf函数,但它本身没有printf的定义,链接器会在标准库(如libc.so或libc.lib)中找到printf的实现,并建立正确的关联。 - 重定位:调整代码和数据中的地址,因为合并后,所有函数和变量的地址都发生了变化,链接器需要修正这些地址引用,使其指向最终的正确位置。
如何生成最终的可执行文件?
直接使用 gcc,不指定 -E, -S, -c:
gcc hello.c -o hello
或者分步来:
gcc -c hello.c -o hello.o gcc hello.o -o hello
hello(在 Linux/macOS)或 hello.exe(在 Windows)就是最终的可执行文件,在 Linux/macOS 下,可以用 file 命令查看:
file hello # 输出: hello: ELF 64-bit LSB executable, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 3.2.0, BuildID[sha1]=...
这表明它是一个可执行的、动态链接的 ELF 文件。
一个完整的命令行示例
假设我们有以下 main.c 和 utils.c 文件:
main.c
#include <stdio.h>
extern void print_message(); // 声明一个在别处定义的函数
int main() {
printf("This is from main.c\n");
print_message();
return 0;
}
utils.c
#include <stdio.h>
void print_message() { // 定义这个函数
printf("This is a message from utils.c\n");
}
编译过程:
-
分别编译为目标文件
gcc -c main.c -o main.o gcc -c utils.c -o utils.o
main.o知道有一个叫print_message的函数,但不知道它的具体实现。utils.o包含了print_message的实现。 -
链接,生成最终可执行文件
gcc main.o utils.o -o my_program
链接器将
main.o和utils.o合并,解决了main.o对print_message的引用,生成了my_program。 -
运行
./my_program
输出:
This is from main.c This is a message from utils.c
常见的编译错误类型
理解了编译过程,就能更好地理解错误信息:
- 预处理阶段错误:通常是
#include的文件找不到或宏定义有语法问题。 - 编译阶段错误:这是最常见的错误,如语法错误(缺少分号)、类型错误、未声明的变量等,编译器会告诉你错误发生在哪个文件的哪一行。
- 链接阶段错误:通常是“未定义的引用”或“符号无法解析”,你调用了
printf但忘记链接 C 标准库(gcc main.c -o main会自动链接,但如果你写gcc main.c -o main -nostdlib就会报错),或者函数名拼写错误(printtf而不是printf)。
现代构建工具
对于大型项目,手动输入 gcc 命令非常繁琐,出现了更高级的构建工具,它们可以自动化整个编译和链接过程,只重新编译发生变化的文件。
- Make / Makefile:最经典的工具,通过读取
Makefile文件中的规则来管理项目。 - CMake:更现代、跨平台的工具,它会生成不同平台(如 Makefile, Visual Studio 项目)所需的构建文件,然后由底层工具(如 Make, Ninja)来完成实际编译。
- Ninja:一个专注于速度的构建工具,由 CMake 等工具生成。
理解手动编译的过程是学习这些高级工具的基础。


