什么是浮点数?
在计算机中,数字有两种主要的表示方式:
(图片来源网络,侵删)
- 整数:用于表示没有小数部分的数字,如
-10,0,100,它们是精确的。 - 浮点数:用于表示带有小数部分的数字,如
14,-0.001,5e10,它们是近似的,用科学记数法的形式来存储。
“浮点”这个名字来源于小数点的位置是“浮动”的,而不是固定的。45 可以表示为 2345 * 10^2,这里小数点就在 1 和 2 之间。
float vs double:核心区别
float 和 double 都是用来表示浮点数的,但它们在精度和占用内存大小上有显著的区别。
| 特性 | float (单精度浮点数) |
double (双精度浮点数) |
|---|---|---|
| 英文名 | Single-precision floating-point | Double-precision floating-point |
| 关键字 | float |
double |
| 内存大小 | 通常为 4 字节 (32 位) | 通常为 8 字节 (64 位) |
| 有效数字 | 约 6-7 位十进制数字 | 约 15-16 位十进制数字 |
| 指数范围 | 较小 | 较大 |
| 精度 | 较低 | 较高 |
| 速度 | 在某些旧架构或特定硬件上可能稍快 | 现代CPU通常对 double 运算有优化,速度与 float 相当或更快 |
| 后缀 | 使用 f 或 F (如 14f) |
无后缀 (如 14),或使用 l/L (不推荐) |
内存大小与精度详解
这是两者最根本的区别,也是你选择使用哪个类型的关键。
float (单精度)
- 大小:32 位(4 字节)。
- 内部结构:这 32 位被划分为三部分:
- 1 位:符号位(正或负)
- 8 位:指数位(决定数值的大小范围,即 10 的多少次方)
- 23 位:尾数位(决定数值的精度,即具体是多少)
- 精度:由于只有 23 位存储尾数,它能提供的精确十进制数字大约是 6 到 7 位,这意味着如果你有一个
float变量x = 123.456789,它很可能只能精确存储到45679,后面的数字就是不可靠的了。
double (双精度)
- 大小:64 位(8 字节)。
- 内部结构:这 64 位被划分为三部分:
- 1 位:符号位(正或负)
- 11 位:指数位(比
float更大,能表示更大或更小的范围) - 52 位:尾数位(比
float多一倍多,精度大大增加)
- 精度:由于有 52 位存储尾数,它能提供的精确十进制数字大约是 15 到 16 位,这对于绝大多数科学计算、金融计算等应用场景已经足够。
简单比喻:

(图片来源网络,侵删)
float就像一个普通的计算器,它能显示 8 位数字,但只有前 6-7 位是精确的。double就像一个科学计算器,它能显示 16 位数字,并且前 15-16 位都是精确的。
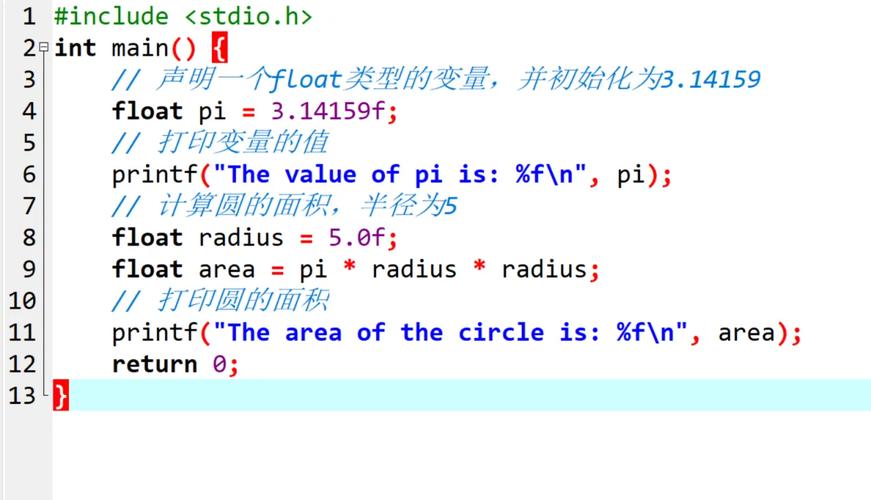
代码示例
让我们通过代码来直观感受它们的区别。
示例 1:基本声明与赋值
#include <stdio.h>
int main() {
// 声明 float 和 double 变量
float f_num = 3.14159265358979323846;
double d_num = 3.14159265358979323846;
// 使用 %f 打印 float
// 使用 %lf 打印 double (注意这个 l!)
printf("The value of float f_num is: %.20f\n", f_num);
printf("The value of double d_num is: %.20f\n", d_num);
return 0;
}
可能的输出:
The value of float f_num is: 3.14159274101257324219
The value of double d_num is: 3.14159265358979311600分析:
- 我们可以看到,
floatf_num在第 8 位 (2之后) 就开始出现错误,后面的数字都是不准确的。 - 而
doubled_num的精度高得多,前 15 位都保持了原样。
重要提示:在 C 语言的
printf函数中:(图片来源网络,侵删)
- 打印
float使用%f。- 打印
double必须使用%lf,虽然在一些编译器下%f也能工作,但%lf是标准且正确的做法,能保证代码的可移植性。

示例 2:后缀的使用
如果你想在代码中明确表示一个浮点数是 float 类型,可以使用后缀 f 或 F,如果不使用后缀,编译器会默认将其作为 double 类型处理。
#include <stdio.h>
int main() {
float f1 = 3.14; // 3.14 被当作 double,然后隐式转换为 float
float f2 = 3.14f; // 3.14f 直接被当作 float,更明确,避免了潜在的精度丢失警告
double d1 = 3.14; // 直接是 double
// double d2 = 3.14f; // 错误!不能将精度较低的 float 赋给精度较高的 double(不进行强制转换时)
printf("f1 = %f, f2 = %f\n", f1, f2);
printf("d1 = %lf\n", d1);
return 0;
}
何时使用 float,何时使用 double?
这是一个非常实际的问题。
优先使用 double 的情况(90% 的情况)
- 默认选择:除非你有非常特殊且充分的理由,否则总是默认使用
double。 - 高精度要求:当你的计算需要高精度,比如科学计算、工程模拟、金融分析等。
- 避免累积误差:在循环中进行大量浮点运算时,使用
float的精度损失会不断累积,最终导致结果严重偏离。double能极大地减缓这种累积效应。 - 现代硬件:CPU 对
double的运算已经进行了深度优化,其速度和float相差无几,甚至更快,为了精度而牺牲一点点(或没有)性能是完全值得的。
可以考虑使用 float 的情况
- 内存极度受限:当你需要处理海量数据,并且每个字节都至关重要时(在 3D 图形学中处理数百万个顶点的坐标,或在嵌入式系统上运行)。
float只占double一半的内存。 - 数据带宽受限:在需要通过网络或从磁盘读取大量浮点数据时,使用
float可以减少数据传输量。 - 精度要求极低:在一些对精度要求不高的场景,比如简单的游戏 UI 显示、动画插值等,
float的精度已经足够。
重要的注意事项
浮点数不精确性
永远不要使用 或 来直接比较两个浮点数是否相等,由于它们的存储方式是近似值,两个在数学上相等的计算结果,在计算机内部的二进制表示可能略有不同。
错误示例:
float a = 0.1 + 0.2;
if (a == 0.3) {
// 这里的代码可能永远不会执行!
printf("Equal!\n");
}
正确做法: 定义一个很小的“误差范围”(epsilon),然后判断两个数的差值是否在这个范围内。
#include <stdio.h>
#include <math.h> // 用于 fabsf 函数
int main() {
float a = 0.1f + 0.2f;
float b = 0.3f;
float epsilon = 0.00001f; // 定义一个很小的误差范围
if (fabsf(a - b) < epsilon) {
printf("a and b are effectively equal.\n");
} else {
printf("a and b are not equal.\n");
}
return 0;
}
字面量默认为 double
像 14 这样的浮点字面量,C 语言会将其视为 double 类型,如果你想把它赋给一个 float 变量,编译器会进行隐式类型转换(可能会有警告),使用 14f 可以让编译器直接将其当作 float,更高效且明确。
| 特性 | float |
double |
|---|---|---|
| 核心 | 单精度,32位 | 双精度,64位 |
| 精度 | 低 (6-7位) | 高 (15-16位) |
| 内存 | 小 (4字节) | 大 (8字节) |
| 使用场景 | 内存敏感、精度要求低的场合 | 通用默认选择、高精度计算 |
| 原则 | 除非必要,否则不要用。 | 除非必要,否则都用它。 |
对于初学者来说,请记住这个简单的法则:在 C 语言中进行浮点数计算时,直接使用 double,这能帮你避免绝大多数由精度不足引起的 bug。


