C语言没有内置的 var_dump() 函数,这是因为C是一门静态类型、需要手动管理内存的语言,不像PHP是动态类型的解释型语言。

(图片来源网络,侵删)
var_dump() 的核心作用是:
- 显示变量的类型。
- 显示变量的值。
在C语言中,要实现类似功能,我们需要手动为每种数据类型编写打印逻辑,下面我将从简单到复杂,介绍几种实现方式。
基础实现(针对基本数据类型)
这是最直接的方法,为每种常见的基本数据类型创建一个打印函数。
代码示例:

(图片来源网络,侵删)
#include <stdio.h>
#include <string.h>
// 打印整数
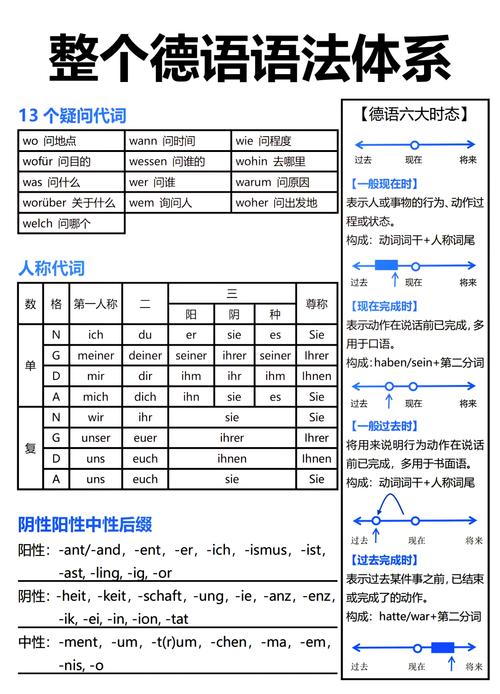
void dump_int(const char *name, int value) {
printf("%s (int) = %d\n", name, value);
}
// 打印浮点数
void dump_float(const char *name, float value) {
printf("%s (float) = %f\n", name, value);
}
// 打印双精度浮点数
void dump_double(const char *name, double value) {
printf("%s (double) = %lf\n", name, value);
}
// 打印字符
void dump_char(const char *name, char value) {
printf("%s (char) = '%c' (ASCII: %d)\n", name, value, value);
}
// 打印字符串(C风格字符串)
void dump_string(const char *name, const char *value) {
printf("%s (char[]) = \"%s\" (length: %zu)\n", name, value, strlen(value));
}
int main() {
int age = 30;
float price = 19.99f;
double pi = 3.14159265359;
char grade = 'A';
const char *name = "Alice";
// 调用我们自己的 "dump" 函数
dump_int("age", age);
dump_float("price", price);
dump_double("pi", pi);
dump_char("grade", grade);
dump_string("name", name);
return 0;
}
输出结果:
age (int) = 30
price (float) = 19.990000
pi (double) = 3.141593
grade (char) = 'A' (ASCII: 65)
name (char[]) = "Alice" (length: 5)优点:
- 简单直观,易于理解。
- 对于少量变量的调试非常有效。
缺点:
- 代码冗余:每次打印都需要手动调用正确的函数。
- 扩展性差:每增加一种新类型,都需要编写一个新的
dump_xxx函数。 - 无法处理复合类型:如结构体、数组等。
使用宏(Macro)实现更简洁的调用
我们可以利用C语言的宏(Macro)来简化调用,让它看起来更像 var_dump(),宏在预处理阶段进行文本替换,可以让我们用更少的代码完成同样的事情。
(图片来源网络,侵删)
代码示例:
#include <stdio.h>
#include <string.h>
// 定义宏,自动传递变量名和值
#define DUMP_INT(v) printf(#v " (int) = %d\n", v)
#define DUMP_FLOAT(v) printf(#v " (float) = %f\n", v)
#define DUMP_DOUBLE(v) printf(#v " (double) = %lf\n", v)
#define DUMP_CHAR(v) printf(#v " (char) = '%c' (ASCII: %d)\n", v, v)
#define DUMP_STRING(v) printf(#v " (char[]) = \"%s\" (length: %zu)\n", v, strlen(v))
int main() {
int age = 30;
float price = 19.99f;
double pi = 3.14159265359;
char grade = 'A';
const char *name = "Alice";
// 使用宏,调用变得非常简洁
DUMP_INT(age);
DUMP_FLOAT(price);
DUMP_DOUBLE(pi);
DUMP_CHAR(grade);
DUMP_STRING(name);
return 0;
}
输出结果:
age (int) = 30
price (float) = 19.990000
pi (double) = 3.141593
grade (char) = 'A' (ASCII: 65)
name (char[]) = "Alice" (length: 5)#v 的作用:
是C语言宏中的一个特殊操作符,称为“字符串化操作符”(Stringizing Operator),它会将其后的宏参数转换成一个字符串字面量。#v 会变成变量名 age、price 等。
优点:
- 调用简洁:
DUMP_INT(age)比dump_int("age", age)简短得多。 - 不易出错:不需要手动输入变量名,宏会自动处理。
缺点:
- 仍然是静态的:每种类型都需要一个宏,无法处理未知类型或复合类型。
- 调试复杂:宏在预处理阶段被替换,如果宏有错误,编译器给出的错误信息可能指向宏定义的位置,而不是你使用它的地方,这会增加调试难度。
处理复合数据类型(结构体和数组)
C语言的强大之处在于处理结构体,我们可以为结构体编写一个专门的 dump 函数。
代码示例:
#include <stdio.h>
#include <string.h>
// 定义一个结构体
struct Person {
char name[50];
int age;
float height;
};
// 打印结构体
void dump_person(const char *name, const struct Person *p) {
printf("--- %s (struct Person) ---\n", name);
printf(" .name = \"%s\"\n", p->name);
printf(" .age = %d\n", p->age);
printf(" .height = %.2f\n", p->height);
printf("-------------------------\n");
}
// 打印整数数组
void dump_int_array(const char *name, const int *arr, size_t size) {
printf("--- %s (int[%zu]) ---\n", name, size);
for (size_t i = 0; i < size; i++) {
printf(" [%zu] = %d\n", i, arr[i]);
}
printf("----------------------\n");
}
int main() {
struct Person p1 = {"Bob", 25, 1.80f};
int scores[] = {88, 92, 76, 99};
size_t score_count = sizeof(scores) / sizeof(scores[0]);
dump_person("p1", &p1);
dump_int_array("scores", scores, score_count);
return 0;
}
输出结果:
--- p1 (struct Person) ---
.name = "Bob"
.age = 25
.height = 1.80
-------------------------
--- scores (int[4]) ---
[0] = 88
[1] = 92
[2] = 76
[3] = 99
----------------------优点:
- 能够处理复杂的、自定义的数据结构。
- 输出格式清晰,易于阅读。
缺点:
- 需要为每种结构体类型编写专门的
dump函数,这非常繁琐,尤其是当结构体嵌套时。
终极方案(反射/代码生成)
对于大型项目,手动为每个结构体写 dump 函数是不现实的,更高级的解决方案是使用反射或代码生成技术。
思想:
- 约定规则:为你的结构体成员添加特殊的标记,比如宏。
- 代码生成:写一个独立的脚本(例如用Python、Perl或Shell脚本),在编译前扫描你的头文件(
.h文件)。 - 自动生成代码:脚本根据约定的规则,自动生成对应的
dump_xxx函数的C代码。 - 编译使用:将生成的C代码包含到你的项目中一起编译。
一个简化的例子(概念性):
假设你的结构体是这样定义的:
// person.h
#include "dump_utils.h" // 引入我们的标记宏
STRUCT_BEGIN(Person)
FIELD_STRING(name, 50)
FIELD_INT(age)
FIELD_FLOAT(height)
STRUCT_END()
你的 dump_utils.h 可能包含这样的宏:
// dump_utils.h
#define STRUCT_BEGIN(name) void dump_##name(const char *var_name, const name *s)
#define FIELD_INT(member) printf(" ."#member" = %d\n", s->member);
// ... 其他类型的宏
// person.h 的展开后类似这样:
// void dump_Person(const char *var_name, const Person *s)
// {
// printf("--- %s (struct Person) ---\n", var_name);
// printf(" .name = %s\n", s->name); // FIELD_STRING 的实现会更复杂
// printf(" .age = %d\n", s->age);
// printf(" .height = %f\n", s->height);
// printf("-------------------------\n");
// }
一个外部脚本会读取 person.h,解析这些宏,并生成最终的 dump_Person 函数,这样你就不需要手动写了。
优点:
- 自动化:极大减少重复劳动,特别是当项目结构频繁变化时。
- 一致性:所有结构体的
dump输出格式保持统一。 - 可维护性高。
缺点:
- 实现复杂:需要建立一套元数据系统,并编写代码生成工具。
- 增加构建步骤:需要在编译前运行脚本。
总结与建议
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 基础函数 | 简单、清晰、易于调试 | 代码冗余、扩展性差 | 快速原型、小型项目、少量变量调试 |
| 宏 | 调用简洁、不易写错名字 | 仍是静态的、调试稍复杂 | 比方案一更优雅的日常调试 |
| 结构体处理 | 能处理复合类型 | 需要为每种类型手动编写 | 中小型项目,有固定结构体需要调试 |
| 代码生成 | 自动化、可维护性高、扩展性强 | 实现复杂、增加构建步骤 | 大型、长期维护的项目,结构体非常多且频繁变化 |
给你的建议:
- 对于个人学习或小型项目:使用 方案二(宏) 是一个很好的平衡点,它既简洁又足够用。
- 对于中型项目,特别是有核心数据结构:可以考虑为关键的结构体编写专门的
dump函数(方案三),或者至少使用宏来辅助。 - 对于大型、复杂的项目:如果调试和日志变得非常关键,那么投入时间研究 方案四(代码生成) 是值得的,它能从长远上节省大量的人力和时间。
别忘了C语言最强大的调试工具:GDB (GNU Debugger),学会使用 gdb 的 print (或 p) 和 info locals 命令,可以让你在不修改代码的情况下检查变量,这通常是调试C程序的首选方法。var_dump() 风格的打印更适合在日志中追踪程序运行状态。


