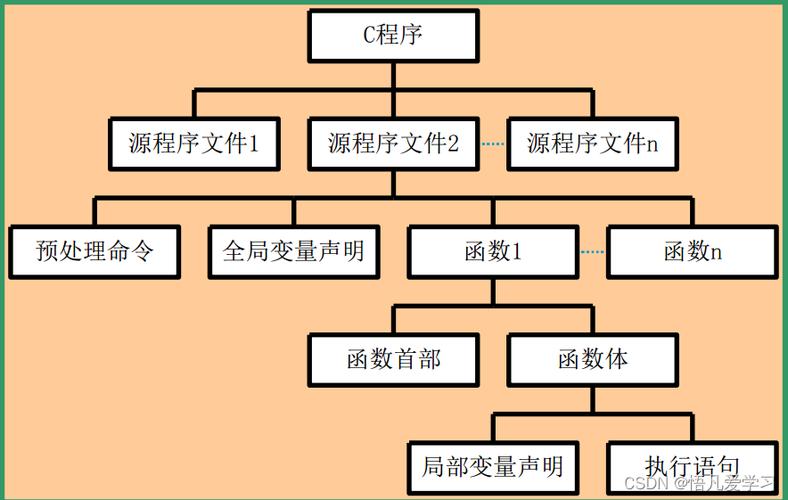
- 核心思想:为什么需要数据结构与算法?
- C 语言基础回顾:实现数据结构的工具
- 核心数据结构详解(C 语言实现)
- 线性结构:数组、链表、栈、队列
- 非线性结构:树、图
- 高级结构:哈希表
- 算法设计策略
- 程序设计实践:如何将它们结合起来
- 学习资源与建议
核心思想:为什么需要数据结构与算法?
想象一下,你要在一个图书馆里找一本书。
- 没有结构(乱放):你可能需要一本一本地翻,直到找到为止,如果书很多,这个过程会非常慢,这就像在一个无序的数组里查找元素。
- 有结构(按字母顺序排好):你可以直接去字母 'C' 开头的区域,然后在该区域内再查找,效率大大提高,这就像在一个有序的数组或二叉搜索树里查找。
数据结构就是研究如何组织和存储数据的学科,以便我们可以高效地访问和修改这些数据。
算法是解决特定问题的一系列清晰、有限的步骤,它定义了操作的顺序。
数据结构与程序设计就是将这两者结合起来:选择合适的数据结构来表示问题中的数据,然后设计高效的算法来处理这些数据,最终用 C 语言编写出可执行的、高效的程序。
C 语言基础回顾:实现数据结构的工具
C 语言之所以是实现数据结构的理想语言,是因为它提供了对内存的底层控制能力,以下是几个关键概念:
-
指针:数据结构的灵魂,指针是一个变量,其值为另一个变量的地址,通过指针,我们可以:
- 动态地创建和销毁内存(
malloc,free)。 - 实现复杂的结构,如链表、树和图,它们中的节点之间通过指针连接。
- 高地传递大型数据结构,避免昂值的值拷贝。
- 动态地创建和销毁内存(
-
结构体:将不同类型的数据组合成一个单一的、自定义的类型,这是构建复杂数据结构“节点”的基础。
// 定义一个链表节点的结构体 struct Node { int data; // 数据域 struct Node* next; // 指针域,指向下一个节点 }; -
内存管理:
malloc(memory allocation) 用于在堆上动态分配内存,calloc类似,free用于释放内存,这是实现动态数据结构(如链表、动态数组)的关键,避免了静态数组大小固定的限制。 -
函数:将算法封装成可重用的模块,可以编写一个
insertNode()函数来向链表中插入节点。 (图片来源网络,侵删)
(图片来源网络,侵删)
核心数据结构详解(C 语言实现)
下面我们用 C 语言来实现几种最核心的数据结构。
A. 线性结构
数组
- 描述:在内存中连续存储的一组相同类型的数据,优点是随机访问快(
O(1)),缺点是大小固定,插入和删除元素慢(O(n))。 - C 实现:C 语言原生支持数组。
int arr[10]; // 静态数组 int* dynamic_arr = (int*)malloc(10 * sizeof(int)); // 动态数组
链表
-
描述:由一系列节点组成,每个节点包含数据和指向下一个节点的指针,内存空间不连续,大小动态可变,优点是插入和删除快(
O(1),已知位置),缺点是随机访问慢(O(n))。 -
C 实现:必须使用结构体和指针手动实现。
// 节点定义 struct Node { int data; struct Node* next; }; // 插入节点到链表头部 struct Node* insertAtHead(struct Node* head, int value) { struct Node* newNode = (struct Node*)malloc(sizeof(struct Node)); newNode->data = value; newNode->next = head; return newNode; // 新节点成为新的头节点 }
栈
-
描述:一种后进先出 的数据结构,只允许在一端(栈顶)进行插入(入栈
push)和删除(出栈pop)操作。 -
C 实现:可以用数组或链表实现,这里用数组实现。
#define MAX_SIZE 100 int stack[MAX_SIZE]; int top = -1; // 栈顶指针,-1表示空栈 void push(int value) { if (top == MAX_SIZE - 1) { /* 栈满处理 */ } stack[++top] = value; } int pop() { if (top == -1) { /* 栈空处理 */ } return stack[top--]; }
队列
-
描述:一种先进先出 的数据结构,在队尾插入元素,在队头删除元素。
-
C 实现:通常用循环数组或链表实现,这里用循环数组。
#define MAX_SIZE 100 int queue[MAX_SIZE]; int front = 0, rear = 0; // 队头和队尾指针 void enqueue(int value) { // ... 检查队列是否已满 queue[rear] = value; rear = (rear + 1) % MAX_SIZE; } int dequeue() { // ... 检查队列是否为空 int value = queue[front]; front = (front + 1) % MAX_SIZE; return value; }
B. 非线性结构
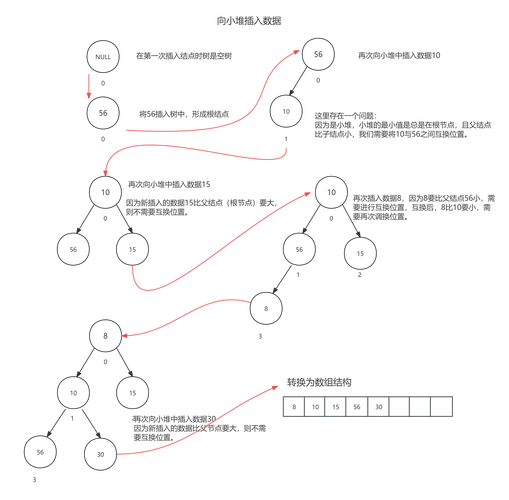
树
-
描述:一种分层的数据结构,由节点和边组成,每个节点有零个或多个子节点,且没有环,最常见的树是二叉树,每个节点最多有两个子节点(左子节点和右子节点)。二叉搜索树 是一种特殊的二叉树,左子树所有值小于根节点,右子树所有值大于根节点,这使得查找非常高效。
-
C 实现:使用结构体和两个指针(左、右)来表示节点。
struct TreeNode { int data; struct TreeNode* left; struct TreeNode* right; }; // 二叉搜索树的查找操作 struct TreeNode* search(struct TreeNode* root, int value) { if (root == NULL || root->data == value) { return root; } if (value < root->data) { return search(root->left, value); } else { return search(root->right, value); } }
图
-
描述:由顶点和边组成,用于表示多对多的关系,图的表示方法主要有两种:
- 邻接矩阵:用一个二维数组表示,
matrix[i][j] = 1表示顶点i和j之间有边,直观,但空间复杂度高(O(V^2))。 - 邻接表:为每个顶点维护一个链表,存储其所有邻接点,空间效率高(
O(V+E)),更常用。
- 邻接矩阵:用一个二维数组表示,
-
C 实现:邻接表实现。
#define V 5 // 顶点数 // 邻接表中的节点 struct AdjListNode { int dest; struct AdjListNode* next; }; // 邻接表 struct AdjList { struct AdjListNode* head; }; // 图结构 struct Graph { int V; struct AdjList* array; }; // 创建新节点 struct AdjListNode* newAdjListNode(int dest) { // ... malloc and return } // 创建图 struct Graph* createGraph(int V) { // ... malloc array of AdjList // for each vertex, set head to NULL }
C. 高级结构
哈希表
-
描述:通过一个哈希函数将键映射到一个数组(哈希表)的索引上,以实现近乎
O(1)的平均查找、插入和删除速度,核心思想是“用空间换时间”。 -
C 实现:实现哈希表需要处理哈希冲突(两个不同的键映射到同一个索引),常用方法有链地址法(每个桶是一个链表)和开放寻址法。
#define TABLE_SIZE 10 struct HashItem { int key; int value; struct HashItem* next; // 用于链地址法 }; struct HashTable { struct HashItem* table[TABLE_SIZE]; }; // 哈希函数 (简单的取模法) int hashFunction(int key) { return key % TABLE_SIZE; } // 插入键值对 void insert(struct HashTable* ht, int key, int value) { int index = hashFunction(key); // 1. 创建新项 // 2. 处理冲突,将新项插入到链表头部 }
算法设计策略
数据结构是“骨架”,算法是“灵魂”,常见的算法设计思想包括:
- 排序算法:对数据进行排序,以便高效查找。
- 冒泡排序、选择排序、插入排序:简单,但效率低(
O(n^2))。 - 归并排序、快速排序:效率高(
O(n log n)),是面试和实际应用中的重点。
- 冒泡排序、选择排序、插入排序:简单,但效率低(
- 查找算法:
- 顺序查找:在无序数据中查找(
O(n))。 - 二分查找:在有序数据中查找(
O(log n))。
- 顺序查找:在无序数据中查找(
- 递归与分治:将大问题分解成小问题来解决,如树的遍历、归并排序。
- 贪心算法:每一步都做出局部最优的选择,期望得到全局最优解,如哈夫曼编码。
- 动态规划:通过存储子问题的解来避免重复计算,如斐波那契数列、背包问题。
程序设计实践:如何将它们结合起来
一个完整的项目流程如下:
- 分析问题:理解需求,确定需要处理哪些数据,以及要对这些数据执行哪些操作(如查找、插入、删除、排序等)。
- 选择数据结构:
- 需要频繁随机访问? -> 数组。
- 需要频繁在中间插入/删除? -> 链表。
- 需要按特定顺序存储和快速查找? -> 二叉搜索树。
- 需要实现撤销/重做功能? -> 栈。
- 需要模拟排队任务? -> 队列。
- 需要最快的查找速度且内存充足? -> 哈希表。
- 设计算法:为选定的数据结构上的操作设计具体的算法,为链表设计一个反转算法。
- C 语言编码:
- 定义结构体来表示数据结构的节点。
- 编写函数来实现各种操作(
create,insert,delete,search,print等)。 - 在
main函数中创建数据结构的实例,并调用你编写的函数来测试和解决问题。
- 测试与调试:使用各种测试用例(边界情况、正常情况、异常情况)来验证你的程序是否正确。
示例:简单的通讯录(用链表实现)
- 数据:姓名、电话号码。
- 操作:添加联系人、查找联系人、删除联系人、显示所有联系人。
- 数据结构选择:链表,联系人数量不固定,添加和删除操作频繁。
- C 语言实现:
- 定义
struct Contact结构体,包含name,phone,next指针。 - 编写
addContact(),searchContact(),deleteContact(),displayAll()函数。 - 在
main函数中提供菜单,让用户选择操作。
- 定义
学习资源与建议
- 经典书籍:
- 《C程序设计语言》:K&R C,C 语言的圣经,打好基础。
- 《数据结构与算法分析:C语言描述》:Mark Allen Weiss 著,理论与实践结合得非常好。
- 《大话数据结构》:通俗易懂,适合入门。
- 在线课程:
Coursera, edX, Udemy 上有大量关于数据结构和算法的课程,很多使用 C 或 C++ 教学。
- 练习平台:
- LeetCode:大量算法题,可以按数据结构和标签刷题,是面试准备的利器。
- HackerRank:提供从基础到进阶的编程挑战。
- 建议:
- 亲手敲代码:不要只看书或看视频,一定要自己把每个数据结构的实现敲一遍,理解其内存布局和操作逻辑。
- 画图理解:对于链表、树、图等结构,画图是最好的理解方式,画出插入、删除、查找操作前后的状态变化。
- 分析复杂度:学习分析算法的时间复杂度和空间复杂度,这是衡量算法优劣的核心标准。
- 先模仿,再创造:先理解并复现经典的实现,然后尝试自己设计新的数据结构或优化现有算法。
希望这份详细的指南能帮助你系统地学习“数据结构与程序设计(C 语言描述)”!这是一个非常有挑战性但回报丰厚的领域。


